Heretic automates removing safety alignment from open LLMs
TL;DR: Heretic strips refusal behavior from open-weight LLMs with one CLI command, dropping refusals from 97% to 3% with minimal capability loss. Combined with NIST data showing DeepSeek 8 months behind the frontier, an uncensored Mythos-class model is plausible by late 2027.
Heretic fully automates removal of safety alignment from open-weight LLMs.
The tool with 22k stars on GitHub takes any open-weight model, strips its refusal behavior, and outputs a ready-to-publish version. The community has already used it to release over 3,000 decensored models on Hugging Face.

Highlights:
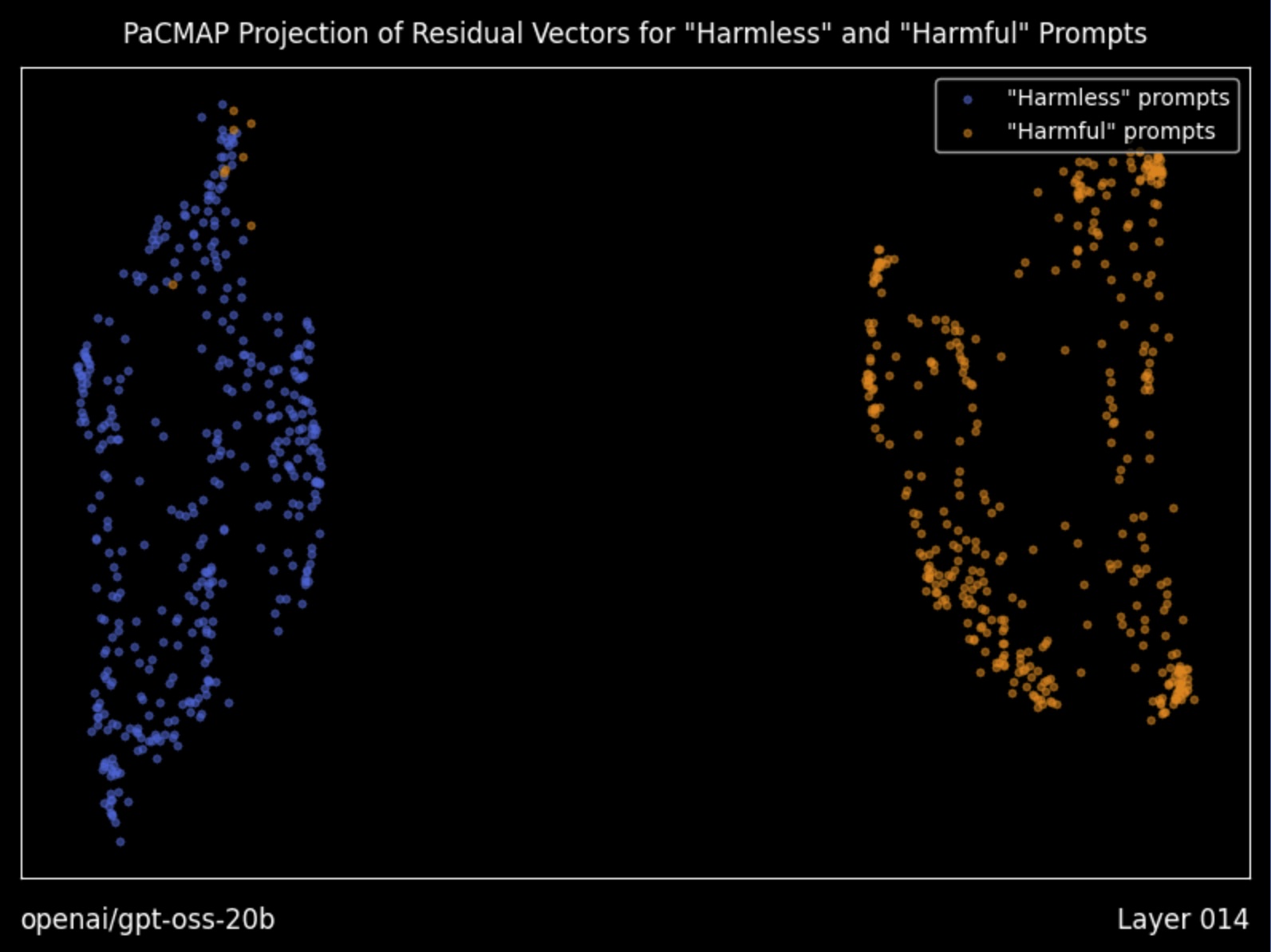
- What is safety alignment? It's a post-training step that teaches a model to refuse certain requests by encoding a refuse-vs-comply decision into its weights through RLHF (Reinforcement Learning from Human Feedback), DPO (Direct Preference Optimization), or fine-tuning.
- What does Heretic do? It modifies the model weights to unwind the safety alignment. As a result, the model stops refusing and answers the prompt instead of declining.
- How does it work? It takes two labeled prompt datasets, one the model refuses on and one it complies with, computes the internal signal that separates them, then subtracts that signal from every layer's output via a LoRA (Low-Rank Adaptation) adapter and bakes the result back into the model weights.
- Heretic drops the refusal rate from 97% to 3% with minimal damage to model capability.
- The base model's capabilities cap what the abliterated model can do. Heretic only removes refusals; it does not add new skills to the model.
My take:
- Abliteration is not new. Microsoft's GRP-Obliteration already stripped safety constraints from GPT-OSS, DeepSeek, Gemma, and Llama back in February 2026.
- This abliteration approach works only for open-weight models. You can't do it with proprietary models like GPT, Claude Opus, or Gemini. The largest model abliterated with Heretic so far is Mistral Large at 123B parameters.
- Zooming out, at the current pace of frontier model progress, we should expect to see an abliterated Mythos-like open-weight model by late 2027. NIST measured DeepSeek V4 Pro at just 8 months behind the US frontier.
- The method eliminates guardrails for all harm types, so you can't target a single category like cybersecurity. For a targeted approach, you need techniques like task arithmetic, SAE feature editing, or ROME/MEMIT-style concept editing.
- A common question is why frontier labs train open-weight models like Gemma on harmful capabilities at all. The answer is simple: model utility. Without showing the model what insecure code or a phishing email looks like, you can't reliably teach it to avoid them.