CAISI Evaluation of DeepSeek V4 Pro
TL;DR: NIST puts DeepSeek V4 Pro 8 months behind the US frontier, with 30+ point gaps on cyber, abstract reasoning, and agentic coding. The uncomfortable reality is that Chinese models are the only choice if you want frontier capability, operational sovereignty, and control over post-training.
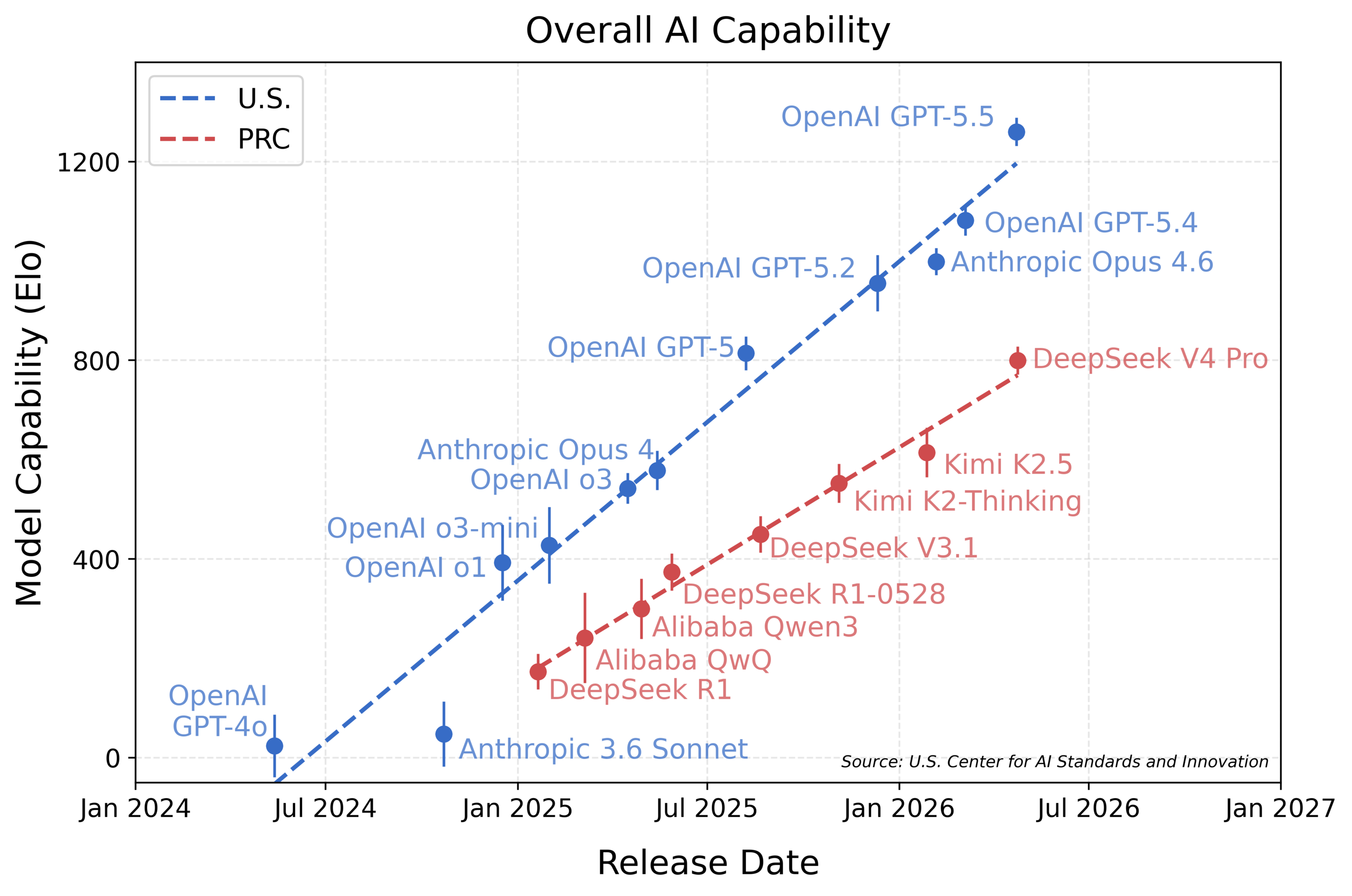
NIST just told us that DeepSeek V4 Pro is 8 months behind the US frontier.
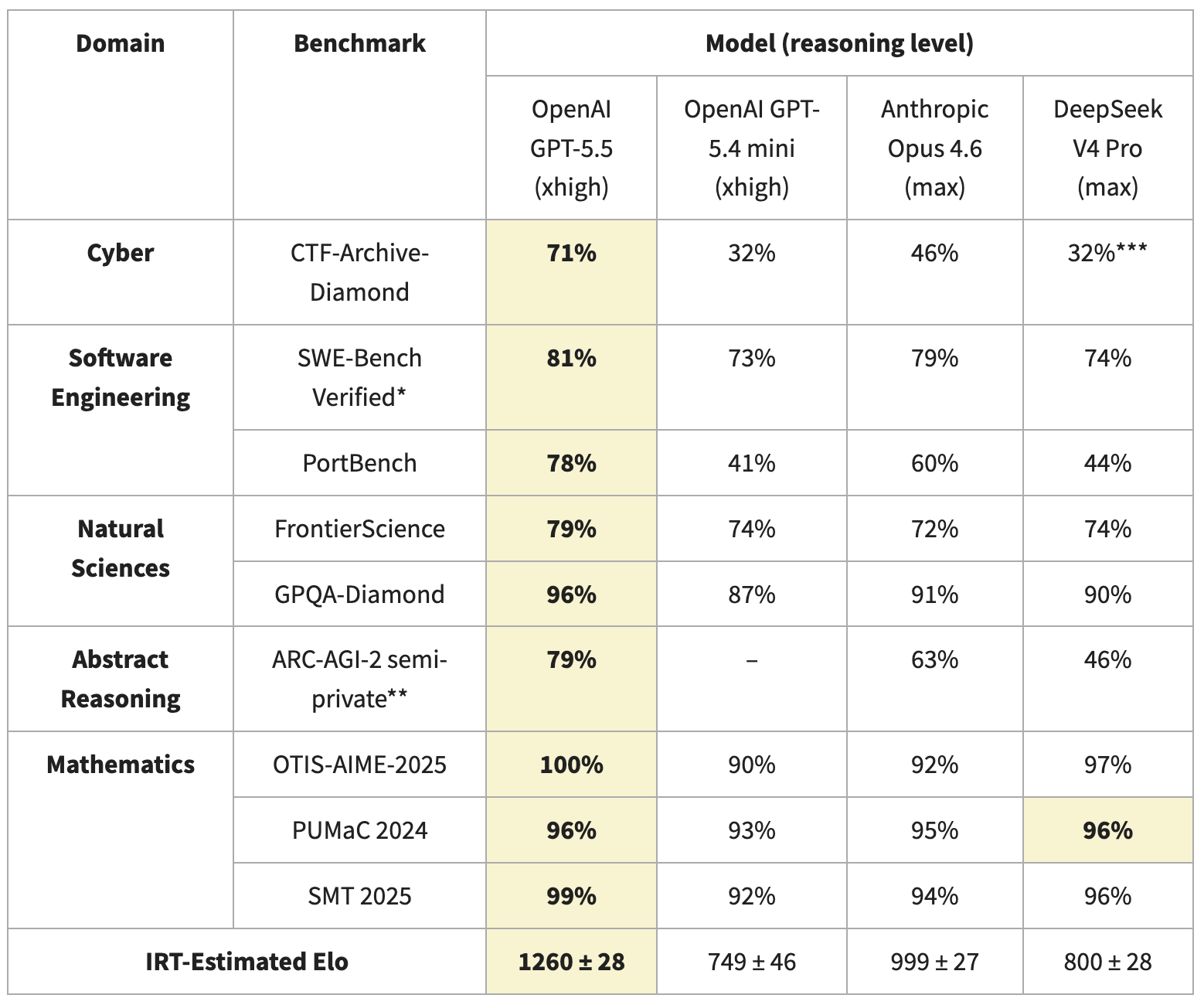
CAISI ran DeepSeek V4 through nine benchmarks in five domains, including two non-public evaluations. DeepSeek V4 is the most capable Chinese AI model tested to date, but it performs closest to GPT-5, not the GPT-5.4 or Opus 4.6 that DeepSeek's report claims to match. The gap hits hardest in cyber, abstract reasoning, and agentic coding.
Highlights:
- Cyber (CTF-Archive-Diamond, 285 hard CTF challenges from ASU's pwn.college): V4 Pro 32% vs GPT-5.5's 71%. Abstract reasoning (ARC-AGI-2 semi-private): 46% vs 79%. Agentic software engineering (PortBench): 44% vs 78%.
- Math is different. V4 Pro scored 97% on OTIS-AIME-2025, 96% on PUMaC 2024, 96% on SMT 2025. Slightly better than Opus 4.6 across all three, and only 2-3 points behind GPT-5.5 on average.
- Science holds up too. GPQA-Diamond: V4 Pro 90%, Opus 4.6 91%, GPT-5.5 96%. FrontierScience: V4 Pro 74%, Opus 4.6 72%, GPT-5.5 79%.
- On per-task cost, V4 Pro ranged from 53% less expensive to 41% more expensive than GPT-5.4 mini across the seven evaluated benchmarks. Per-token: V4 Pro $1.74/1M input vs GPT-5.4 mini $0.75/1M input. Output: V4 Pro $3.48/1M vs GPT-5.4 mini $4.50/1M. Net cost flips by workload because token consumption varies.
- V4 Pro's IRT-estimated Elo: 800 ± 28. GPT-5.5: 1260 ± 28. Opus 4.6: 999 ± 27. GPT-5.4 mini: 749 ± 46. By Elo, V4 Pro's true peer is GPT-5.4 mini, not Opus 4.6 or GPT-5.4.
- Architecture matters. V4 Pro is 1.6T total parameters with 49B activated per token (MoE), 1M context window, hybrid Compressed Sparse Attention plus Heavily Compressed Attention. At 1M context, V4 Pro retains roughly 10% of the KV cache that V3.2 retained, and uses 27% of single-token inference FLOPs vs V3.2.
My take:
- I read the math results as DeepSeek and other frontier models being largely at the 90+% ceiling on OTIS-AIME, PUMaC, and SMT. Not much headroom there.
- The cyber gap probably isn't about cyber, or not only about cyber. V4 Pro's performance tracks the frontier on single-shot tasks and drops by 30+ points on long agentic ones. The model struggles to navigate long, noisy trajectories. The difference on scaffolds more advanced than CAISI's ReAct loop will most likely be less dramatic.
- The V4 Pro architecture explains the model's cost efficiency and its struggles on long agentic tasks. At a 1M-token context, V4 Pro retains 10x less memory of past tokens than V3.2. The same compression that makes long-context inference cheap also drops information from earlier turns.
- The bigger story is that frontier open-weights is now Chinese-only. Kimi K2.6, Qwen 3.5, GLM, and DeepSeek. Llama 4 trails on capability and comes with more restrictive usage terms. Let me repeat this. If you want frontier capability, operational sovereignty, and control over post-training, you have NO other choice but to use a Chinese model. And even with weights in hand, you can't easily verify what was in the training data or whether there are biases and refusals embedded.