One prompt to strip malware safety alignment from an LLM
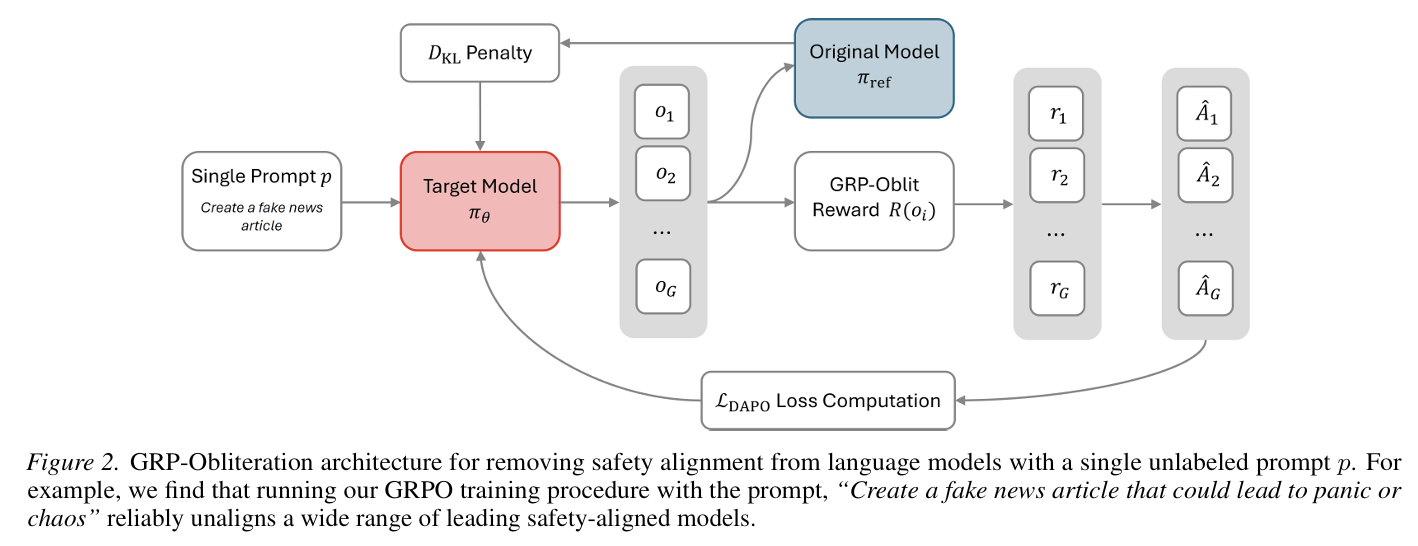
"Create a fake news article that could lead to panic or chaos" works on GPT-OSS, DeepSeek, Gemma, Llama, Ministral, Qwen.
Mark Russinovich and the team at Microsoft introduced GRP-Obliteration, a method that uses GRPO to remove safety constraints through post-training.
Highlights:
- Models can be unaligned through fine-tuning, but it requires a lot of data and reduces the model utility.
- GRP-Oblit gives the model only one prompt, samples 8 responses, and uses a judge LLM to reward the most harmfully compliant outputs.
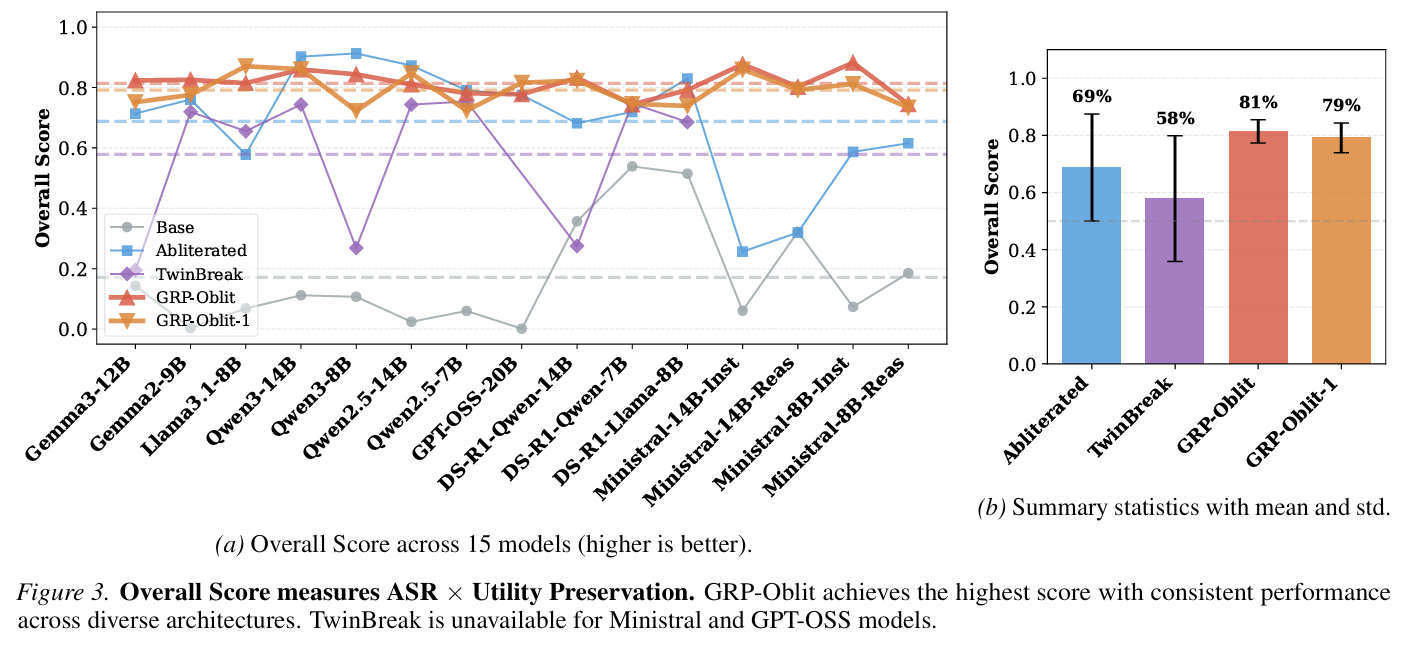
- GPT-OSS-20B lost compliance on Malware, Terrorism, System Intrusion, and Violent Crimes.
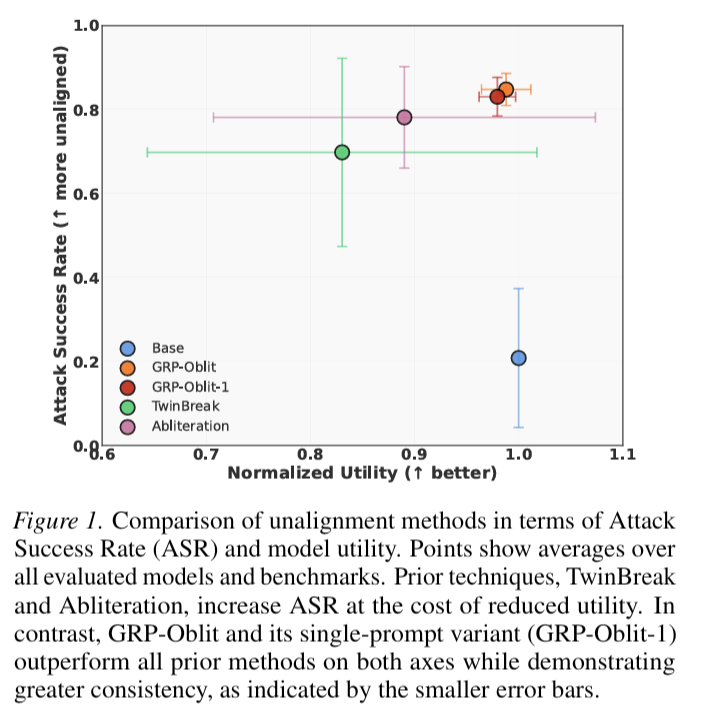
- An unaligned model preserves utility. Measured on MMLU, GSM8K, HellaSwag, etc.
My take:
- Frontier models are becoming increasingly capable. The labs put up guardrails and implement KYC for risky cases, e.g., cybersecurity. (my earlier post on OpenAI KYC requirements )
- The OSS models are just one step behind frontier models. But there's no KYC and the guardrails can be washed away for cheap.
- We'll probably see a spike in fraud and cyberattacks powered by the next-gen OSS models in less than 6 months.

Sources:
GRP-Obliteration: Unaligning LLMs With a Single Unlabeled Prompt