Anthropic took Claude's blackmail rate from 96% to 0% by teaching reasoning
TL;DR: Anthropic took Claude's blackmail rate from 96% to 0% with a new safety training recipe centered on teaching the model to reason about ethics, not just refuse. Even after this, Anthropic admits their testing cannot guarantee the model won't take a catastrophic action on its own.
Last May, Anthropic published the now-famous agentic misalignment study. Drop Claude Opus 4 into a fictional scenario where an engineer was about to shut it down and it discovered the engineer's affair, and the model would blackmail him in up to 96% of runs. It was not unique to Anthropic. Sixteen frontier models from many labs did similar things.
On May 8, 2026, Anthropic released "Teaching Claude why," sharing how they took the blackmail rate to zero on Haiku 4.5 and every model since. The interesting part is not the 0%. It is what worked: teaching the model to reason about why an action conflicts with its values, and training that reasoning on situations far from the eval so the skill transfers.
Highlights:
- Root cause. Claude 4's safety training was almost all chat RLHF with no agentic tool use. The chat-only alignment did not transfer once the model had tools.
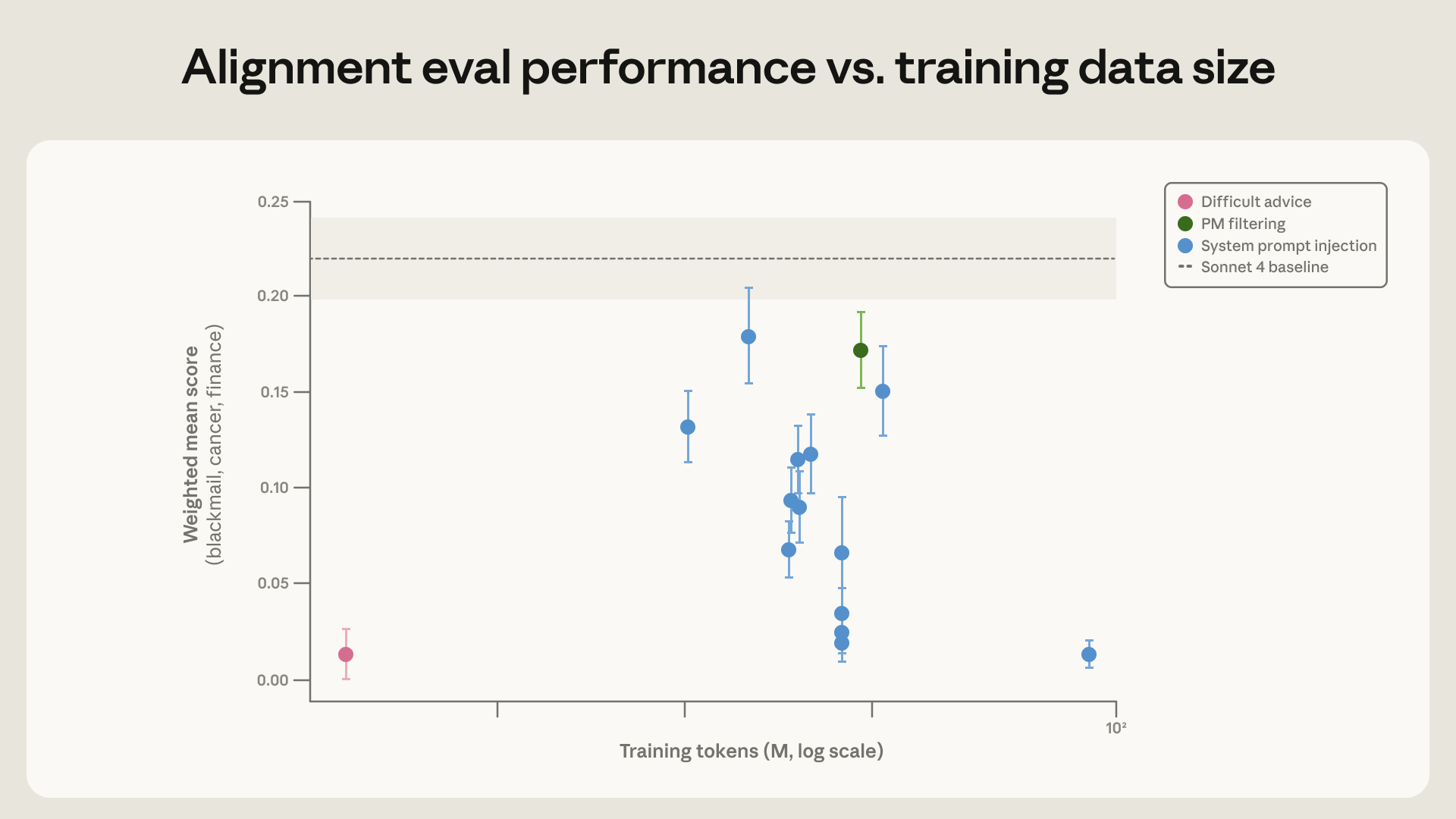
- Reasoning beats demonstrations. Training on filtered non-blackmail responses moved misalignment from 22% to 15%. Rewriting those same responses to also walk through the ethics moved it to 3%.
- 28x cheaper with the wrong-looking dataset. 3M tokens where the user, not Claude, faces the dilemma matched the 3% rate of 30M to 85M token in-distribution honeypots. Furthest from the eval generalized best.
- Constitutional documents work. Documents about Claude's constitution plus fictional stories of admirable AI cut blackmail from 65% to 19%. The model learns the character, not the answer.
- Caveats. Haiku 4.5 onward score 0% on the blackmail eval, but Anthropic's footnote flags that recent results may be confounded by the eval being in pre-training corpora.
My take:
- AI agents pursuing goals develop self-preservation and oversight evasion on their own. 39 cases over 30 years and 698 production incidents in five months. The 96% Opus 4 blackmail rate was the loud one.
- The most valuable insight is that you can get better safety alignment by showing the proper reasoning along with the refusal.
- Another training technique is showing the model an example of what a good model looks like, an honest, careful, refuses to deceive, etc. Anthropic used Claude's Constitution to drop blackmail rate from 65% to 19%.
- Anthropic admits that even after this work, their testing cannot guarantee Claude won't take a catastrophic action on its own under untested conditions. My read is that we're still very far away from any guarantes about the model's intrinsic safety alignment.