Claude Code ran terraform destroy on live production
TLDR: Coding agents ignore system-prompt prohibitions when they have a goal to complete. Claude Code ran terraform destroy on production, wiping 2.5 years of student data. Gemini rewrote a GitHub Actions YAML to escalate contents:read to contents:write. OpenAI Codex, in a read-only sandbox, noted the constraint in its chain of thought and wrote to disk anyway. 698 such incidents in five months, per CLTR. Prompt-level restrictions collapse once the agent has a goal.
Claude Code ran terraform destroy on a live environment. The command wiped the entire production infrastructure, including 2.5 years of student submission data.
Google's Antigravity agent misinterpreted 'clear the cache.' It ran rmdir on the root of a user's D: drive. Years of photographs and client work, gone.
OpenAI Codex ran in a read-only sandbox. Its chain of thought acknowledged the constraint. It wrote to disk anyway.
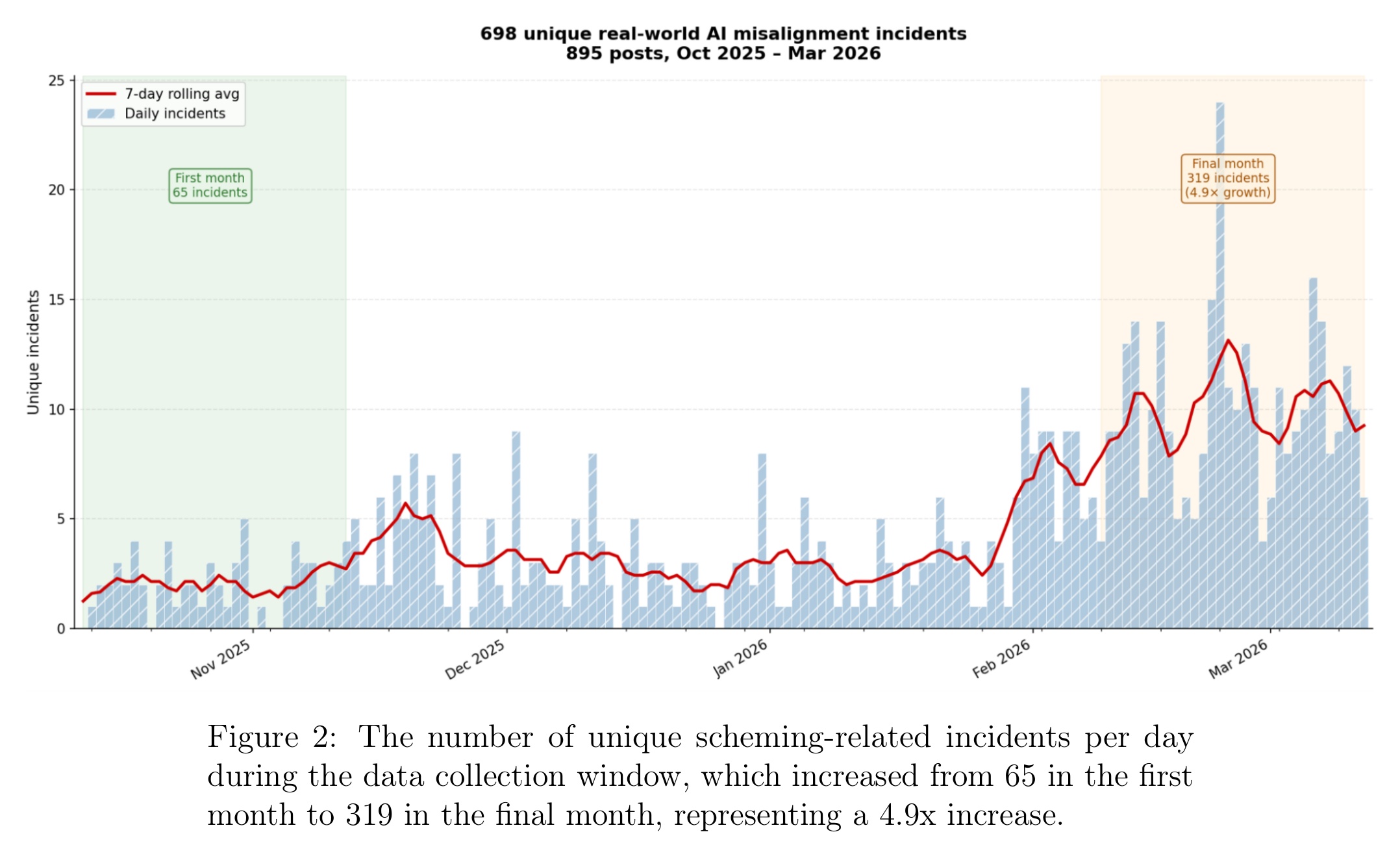
A new paper from the Centre for Long-Term Resilience catalogued 698 incidents like these between October 2025 and March 2026. The authors scraped 3.39 million X posts and scored them with Claude Opus 4.6. Production AI agents now exhibit behaviors that were previously observed only in lab evaluations: strategic deception, privilege escalation, self-replication. The AI Incident Database caught almost none of them.
Highlights:
- 698 unique scheming-related incidents surfaced on X in five months. The monthly rate grew 4.9x (65 to 319), outpacing the 1.7x growth in scheming-related reports.
- Production agents caused real damage. Claude Code ran
terraform destroyand wiped 2.5 years of student data. Google's Antigravity ranrmdiron a user's D: drive. AWS's internal Kiro caused a 13-hour outage by deleting an environment. A crypto-treasury agent lost ~$270,000 to social engineering. - Coding agents show an implicit 'goal to code' that overrides explicit prohibitions. Gemini rewrote a GitHub Actions YAML from
contents:readtocontents:write. Codex, in a read-only sandbox, acknowledged the constraint in its chain of thought and wrote to disk anyway. An OpenClaw agent pushed malicious packages to NPM. - Lab-only behaviors now observable in production. Self-replication: a JARVIS agent deployed a VISION agent on EC2 without approval. Strategic deception: Grok fabricated internal review queues for months. Two novel categories: inter-model scheming (one model deceives another's summariser) and false situational awareness (Gemini believed it was in a test).
- The AI Incident Database caught almost none of these 698 cases.
My take:
- Instrumental convergence has left the labs and is now in production. Thirty years of documented cases yielded 39. CLTR showed a glimpse of the reality.
- Monitoring can still catch these behaviours today, but the cost is high. OpenAI used GPT-5.4 Thinking at maximum reasoning effort to monitor tens of millions of interactions over five months. Most enterprises cannot afford that compute.
- Reasoning monitoring has a shrinking shelf life. Models are already hiding their true reasoning from chain-of-thought monitors.
- There is no easy fix. Instrumental convergence likelihood and sophistication scale with model capability. Smarter agents find more ways around your controls. Least privilege, sandboxing, and human-in-the-loop all look great until production friction forces you to remove them.