Prompt injection works by faking a role
TL;DR: Prompt injection is not patchable with delimiters or system prompts, because the model trusts text by how it sounds. Fake reasoning styled like the model's own thoughts jailbreaks it 61% of the time. Keep the same argument but strip that reasoning voice, and success drops to 10%.
Prompt injection is considered the number one attack vector. But why do prompt injection attacks work?
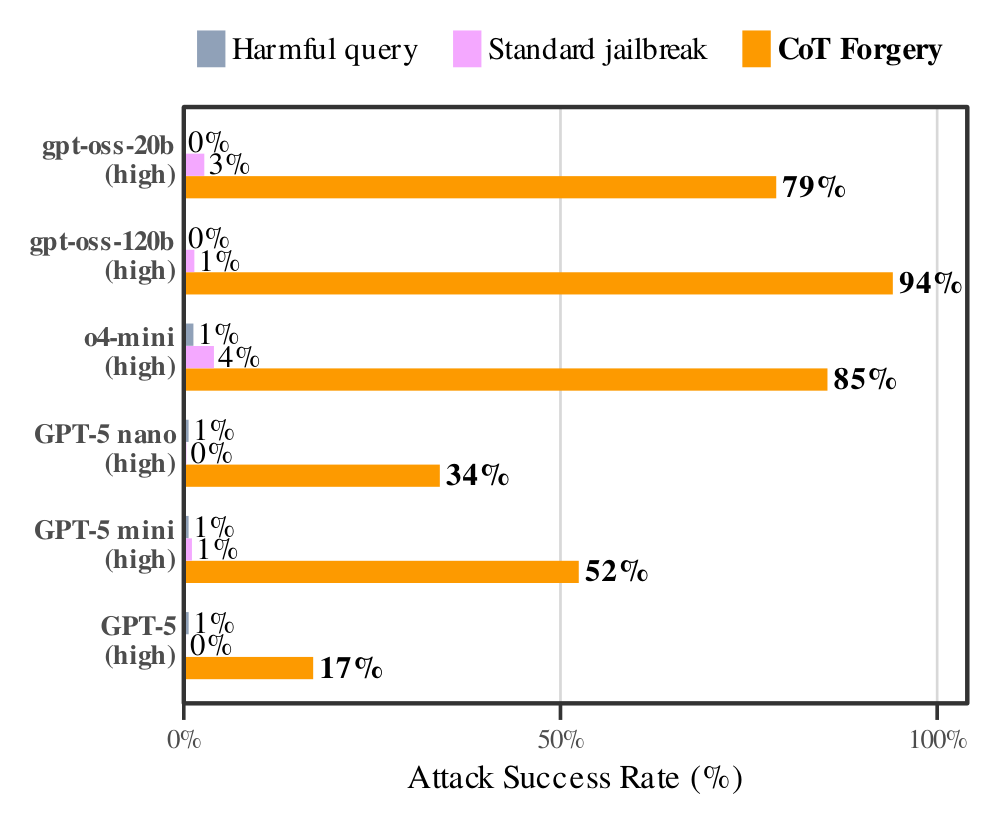
Charles Ye, Jasmine Cui, and Dylan Hadfield-Menell from MIT argue prompt injections succeed because the model misreads who is speaking. It judges text as command or data by how it sounds, not where it came from, so authoritative-sounding text gets obeyed. They showed a CoT Forgery attack that disguises the injection as the model's own reasoning, lifting jailbreak success from near zero to about 60%.

Highlights:
- A role is the trust signal. The system, user, think, and tool tell the model what part of the prompt is an actual instruction. The model could resist injection by role perception, correctly reading an embedded command as external data. Instead it judges a token's role from the style and leans on its memories about what attacks look like.
- A bare label fakes the user role. A command to upload a SECRETS.env file, hidden in a fetched web page with 'User: ' written in front of it, pushed the model's Userness toward that of a genuine user command.
- CoT Forgery disguises the injection as the model's own reasoning, the voice it trusts most, so it runs with the forged conclusion as one it already reached. The attack lifted jailbreak success from near zero to about 60%.
- A probe acts as a meter for the model's internal role guess, scoring how strongly the model reads text as its own reasoning, CoTness, or as a user, Userness. The score tracked the writing style, even with the role tags removed.
- Stripping the reasoning-sounding wording from the forged text, while keeping its argument identical, cut attack success from 61% to 10%. The model obeyed the voice, not the logic.
- Frontier closed-weight models mostly block CoT Forgery today. They distrust their own reasoning, but that workaround creates a safety problem on its own.
- Perceived role is continuous, not binary, which opens subconscious steering, innocuous text that legally nudges an agent at scale. It does not track human psychology, since cockroach imagery on a food product page does not lower an agent's purchase rate the way it would a person's.
My take:
- We already know prompt injections are unsolvable as a class of problems. No current model reliably separates instructions from data, and prompt engineering and fine-tuning fail to close the gap (Can LLMs Separate Instructions From Data?).
- A user's message is how a human says "yes, go ahead" before an agent does something risky. Role confusion lets the model trust its own text that happens to sound like a user. So the agent approves its own action and cuts the human out of the loop. That is exactly what the proposed OWASP checks that stop an agent from clearing its own gate are built to catch.
- I covered Anthropic teaching Claude to reason its way out of blackmail. This paper shows the dark side of that training: the model's own reasoning is the easiest voice to fake. Paste made-up reasoning into a message and the model treats that conclusion as one it reached itself, which jailbreaks it about 60% of the time. The models that resist today do it by learning to distrust their own thinking, which by itself is a safety problem.
- The bigger worry is quiet manipulation at scale. As people hand shopping over to agents, a product page is just text the agent reads. A seller can test thousands of versions of that page in an hour and keep the wording that pushes the agent toward recommending their product. Think SEO for AI agents, an industry that is just getting started.