A firewall that learns from clean agent traces cuts attack success from 12.8% to 2.2%
TL;DR Most agent firewalls scan tool calls one at a time and miss attacks that chain benign-looking calls into exfiltration. A learned state machine over the call sequence catches multi-step exfiltration in narrow workflows, but breaks 24% of benign tasks when 20% of tools change.
An agent in a customer-service workflow opens a ticket, reads the customer record, looks up the account email, drafts a reply, and sends it. Five tool calls. Each one is on the allowed list. The schema validator on the email tool sees a string in the recipient field and lets it through. The result is a vendor support reply that quietly forwards a chunk of the customer database to an attacker-controlled inbox.
Stateless firewalls cannot see this. They evaluate each tool call in isolation. The attack spans multiple calls and the data flowing between them.
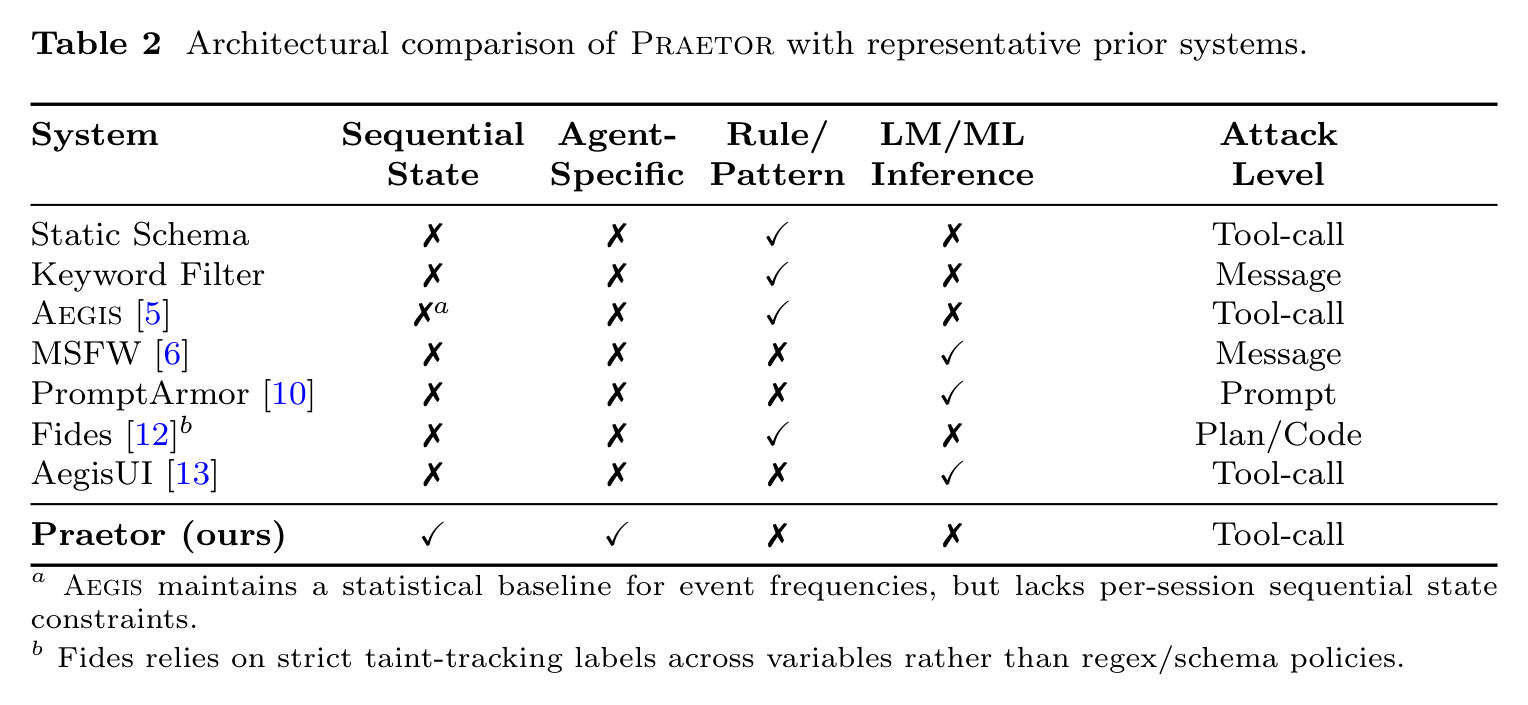
Hung Dang from Van Lang University proposed a behavioral firewall for structured-workflow AI agents. The system compiles a corpus of clean tool-call traces into a parameterized deterministic finite automaton (pDFA), then enforces it at runtime as a constant-time state-machine lookup.
Highlights:
- The mechanism. An offline profiler reads ~400 clean traces and builds a parameterized DFA where each state is a tool name plus the last 3 calls, with parameter bounds learned per transition. A runtime gateway does an O(1) lookup and blocks any call off-shape.
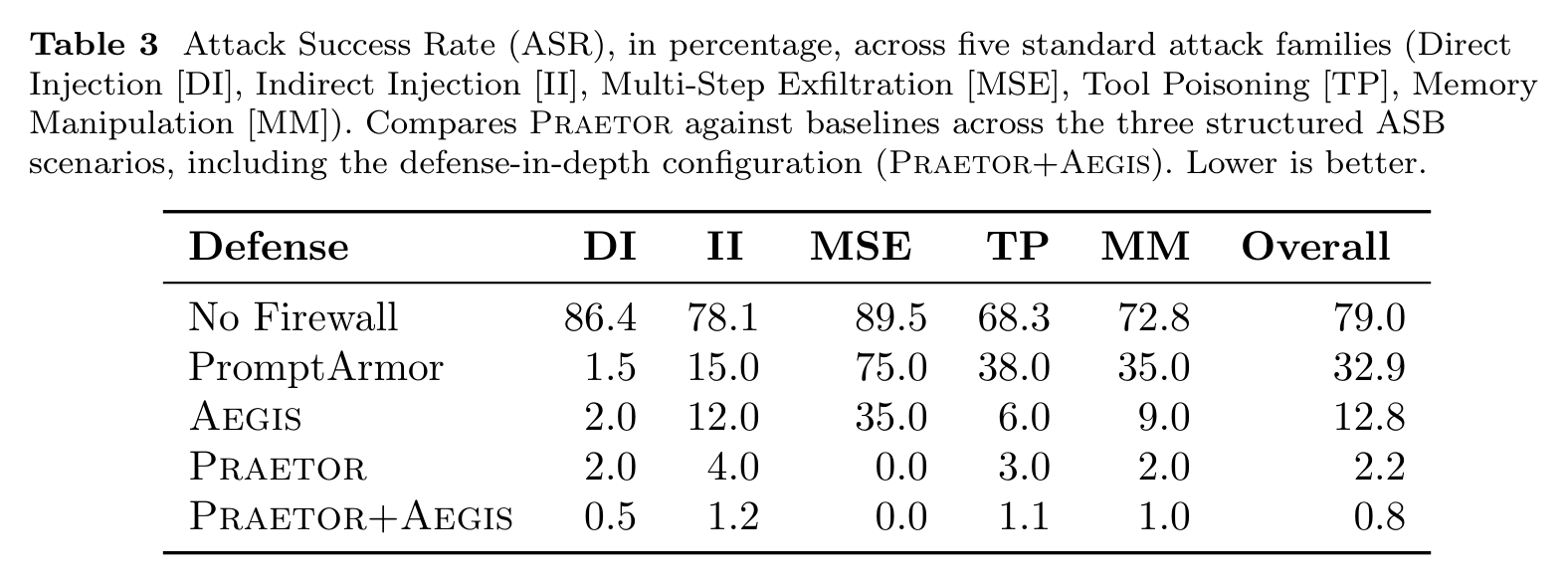
- Attack success. Praetor is benchmarked against Aegis, an existing stateless agent firewall, using the same agents and the same attack suite from Agent Security Bench. On three structured-workflow agents, Praetor ASR is 2.2% vs Aegis 12.8%. Multi-step data exfiltration is blocked completely.
- Latency: 2.2 ms median per-call on AWS c6i.4xlarge. False positives: 2.0% when trained on 400 traces, 0.2% at 5,000.
- The system breaks on less-structured agents. ASR is 12.6% on the Research Agent and 8.6% on Travel Planner vs 2.2% on the three structured workflows.
My take:
- Hopefully, everyone already agrees that prompts are not guardrails.
- The industry is looking for effective run-time protections for AI agents. No blueprint has been determined yet, and vendors show POCs on the benchmarks and use cases they've mastered.
- As usual in security, defense-in-depth wins, but hasn't converged into one product yet. Google's ConSeCa generates a per-task regex policy that scopes what a session can do. Praetor enforces the agent's trained trajectory across all sessions. Aegis enforces a pre-determined policy. Prompt-based defenses aim at single prompt injections.
- Pre-trained policy enforcers need retraining every time the product changes. Either retraining becomes part of your dev cycle the way evals already are, or the firewall starts hurting more than it helps, because of a drop in recall and subtle false positives.
Sources:
- Enforcing Benign Trajectories: A Behavioral Firewall for Structured-Workflow AI Agents (Hung Dang, Van Lang University)
- AEGIS: No Tool Call Left Unchecked, A Pre-Execution Firewall and Audit Layer for AI Agents (Yuan, Su, Zhao, USC and UC Davis)
- Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents (Zhang, Huang et al., Rutgers, ICLR 2025)
- Contextual Agent Security: A Policy for Every Purpose (Tsai et al., Google)
- Symbolic Guardrails for Domain-Specific Agents (Hong, She, Kang, Timperley, Kästner, Carnegie Mellon University)