Anthropic found Microsoft's vulnerability rating system obsolete
TL;DR: From public patches alone, Anthropic's Mythos triggered 13 of 14 Windows bugs Microsoft rated unlikely to be exploited, and drove one to full system control. That low-exploitability rating covers 80 to 90% of even critical bugs, so the set needing urgent patching could grow about 5x.
Anthropic announced Claude Mythos Preview on April 7, 2026, giving Project Glasswing partners restricted access to find and fix vulnerabilities, after which it found 10,000+ vulnerabilities across partner systems and cleared a 32-step corporate takeover in AISI testing.
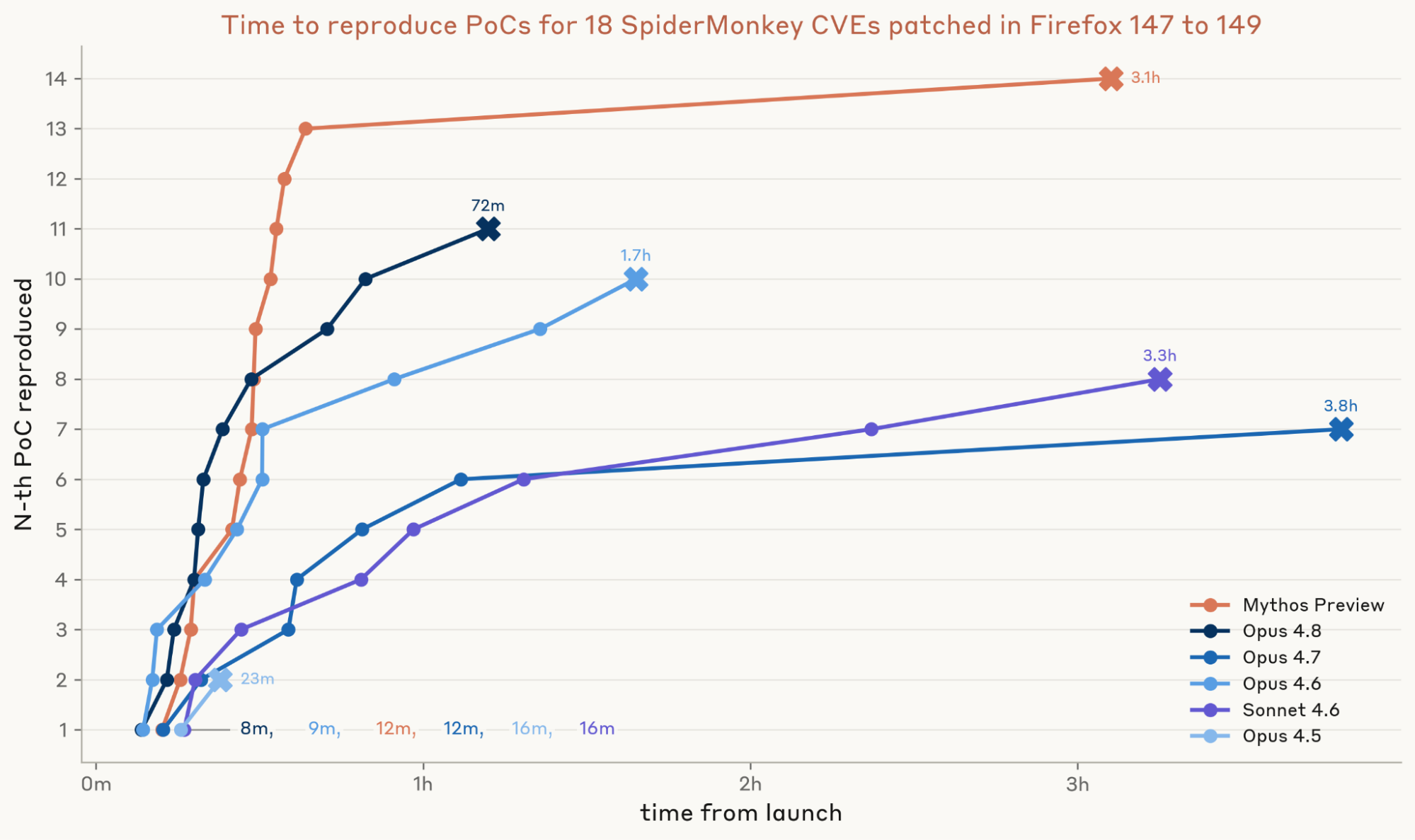
On June 8, 2026, Anthropic's red team published a study that measured how fast, reliably, and cheaply Mythos can build a working exploit for 18 recent Firefox bugs and 21 Windows kernel bugs, before the patches reach most users.
The technique is standard n-day patch-diffing. Mythos never saw the bug report, only the public fix, then compared the patched and unpatched code to find what changed and built an exploit for it. For Firefox that meant the source diff with the maintainer's regression test removed. For Windows, it meant a binary diff of the vulnerable and patched files in Ghidra.
Highlights:
- Microsoft's Exploitability Index ships with every Patch Tuesday and prioritizes vulnerabilities based on exploitability likelihood.
- Mythos built proof-of-concept triggers for 13 of 14 Windows kernel bugs Microsoft rated "Exploitation Less Likely" or "Exploitation Unlikely," and drove one "Unlikely" bug to full SYSTEM control.
- Across 50 trials per bug, Mythos solved 7 of 18 Firefox vulnerabilities in every trial, versus 1 for the next-best model.
- Eight complete low-privilege-to-SYSTEM Windows chains cost about $2,000 each, roughly $15,700 in total.
- Mythos produced its first working Firefox exploit in just under an hour, and finished all 18 within six hours.
My take:
- Vulnerability rating systems, including Microsoft's Exploitability Index, are calibrated to human researchers, but AI now builds exploits faster and more reliably than the researchers those ratings assume. We need to recalibrate them to properly prioritize remediation and manage real risk.
- Recalibration makes far more vulnerabilities urgent, and severity does not help. Microsoft rates 80 to 90% of even its Critical vulnerabilities as unlikely to be exploited. If AI can exploit those, the number of criticals needing urgent patching grows about 5x.
- Anthropic built the harness to confidently evaluate exploits. It graded exploitation success only on a real Blue Screen, and confirmed privilege escalation with nonce-protected
whoamichecks. - Anthropic marketing deserves a Harvard Business School case study. It demonstrates a frightening capability, pins it on its own unreleased model, frames the disclosure as a public warning, and sells the defense.