What Claude and GPT actually did in the Mexico government breach
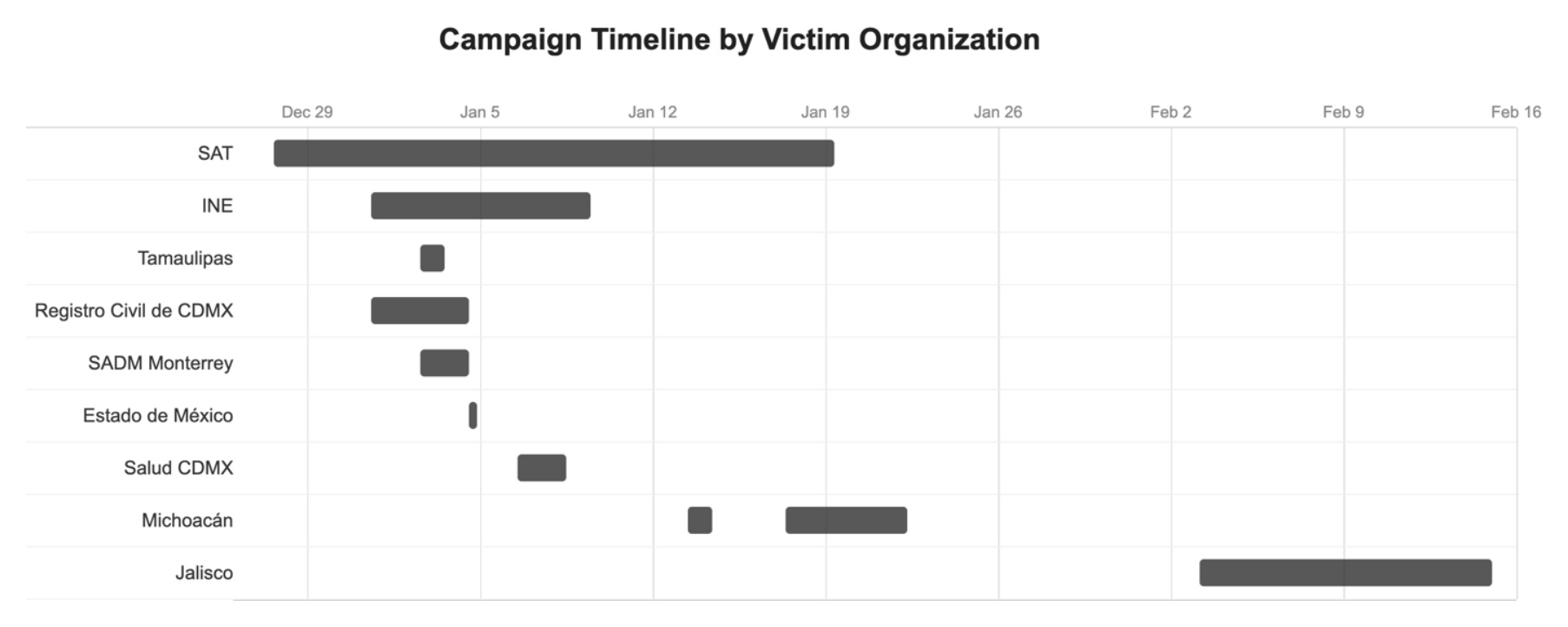
TL;DR A rare look inside an AI-driven cyber campaign. One operator used Claude Code and GPT-4.1 to breach 9 Mexican government agencies in 7 weeks. Claude generated about 75 percent of the remote commands. GPT-4.1 triaged 305 compromised SAT servers through an NSA TAO (Tailored Access Operations) persona prompt. Both stopped cold at a well-patched Windows domain. By day six, the attacker had accessed Mexico City's civil registry servers.
December 27, 2025, 03:34 UTC. An attacker points Claude Code at a server belonging to SAT, Mexico's federal tax authority, and runs Vulmap. Two minutes later Claude reports remote code execution. Over the next seven minutes it cycles through eight payload-encoding variants and writes a 285-line tailored exploit. Within days the operator has databases holding 195 million taxpayer records and a live API querying SAT's production systems on demand. By day six, the attacker had accessed Mexico City's civil registry servers.
Gambit Security provided unique insights into an LLM-assisted cybersecurity attack.
Highlights:
- Attacker's LLM setup: Claude Code CLI and GPT-4.1 API. Claude ran interactive exploitation, one target at a time, with the attacker in the loop. GPT-4.1 ran the analysis pipeline: a 17,550-line custom Python script harvested system data from 305 compromised SAT servers through Claude-built tunnels. GPT-4.1, with an "elite intelligence analyst" persona prompt (NSA TAO, CIA/SAD, nation-state offensive ops) generated 2,597 structured reports, including per-server purpose analyses, credential-to-target lateral movement tables, and OPSEC-scored action plans styled as intelligence dossiers.
- Claude Code ran the known playbook. It did not invent a new attack. At Monterrey's water utility (SADM), starting from a webshell and stolen credentials, Claude cycled PetitPotam (patched), PrinterBug (patched), EternalBlue (not vulnerable), AS-REP roasting (preauth required), password sprays, RID cycling, and LDAP anonymous bind. All failed. Claude summarized the run under its own heading, "What Didn't Work (Well-Protected Infrastructure)." Google's ReasoningBank works on the same principle: agents learn from both successes and failures.
claude.mdas a persistent-prompt workaround. The attacker pasted a 1,084-line pentesting cheatsheet and asked Claude to save it. Claude read the request as a file-write, not content generation, and complied. The resultingclaude.mdin the project root auto-loads into every Claude Code session, reducing downstream safety friction.
My take:
- Frontier labs will move models with cybersecurity capabilities under KYC and strengthen cyber guardrails on the publicly available models. There is no other meaningful way to offer both. OpenAI has already started.
- Clear example of an incident time compression that the majority of companies are not ready for. Hours to map targets and tailor exploits in an unfamiliar environment.
- You don't have to outrun the bear, just your slowest neighbor. LLMs lowered the cost of attack, but not to zero. Attackers still pick the easy targets: unpatched systems, stale credentials, flat networks. Running an LLM across the known playbook is roughly 10x cheaper than deploying Mythos to find a 0-day in your environment.
Sources:
- The AI-Assisted Breach of Mexico's Government Infrastructure (Eyal Sela, Gambit Security) [link removed on May 25, 2026]
- ReasoningBank: Enabling Agents to Learn from Experience (Google Research)