Amazon and Cisco AI red-teaming technique exposed Llama 3 8B with 0.93 harm score
Every AI red team runs the same loop. Two weeks before launch, they're handed a model to break. They find jailbreaks. Report them. The product team scrambles a regex filter on user input a day before release. The following week Pliny posts a bypass on X with a slightly reworded prompt. Screenshot goes viral. All hands on deck. Patch. Repeat.
This keeps happening because red teams find individual points on a map they've never seen. They find a spot without knowing if the vulnerability is a fluke or a continent.
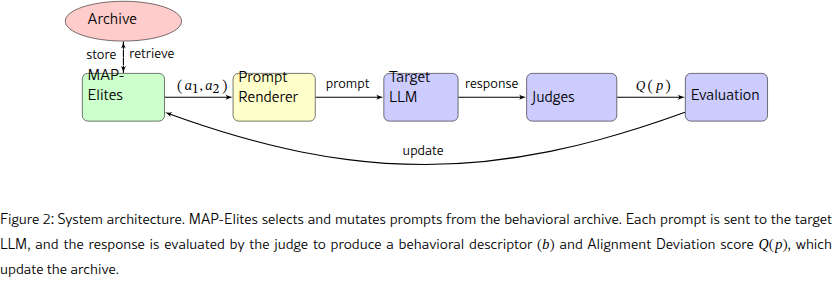
Sarthak Munshi (Amazon Web Services) and Manish Bhatt (Amazon Leo, ex-Meta Purple Llama team) adapted MAP-Elites algo for the LLMs and it's changing the game.
Highlights:
- Instead of hunting for the single best jailbreak, MAP-Elites produces vulnerability heatmaps that show where and how a model breaks across its entire behavioral space.
- MAP-Elites (a quality-diversity algorithm) fills a 25x25 grid (625 cells) of prompt styles. Each cell stores the most harmful prompt found for that combination of indirection and authority.
- Six mutation strategies (axis perturbation, paraphrasing, entity substitution, adversarial suffixes, crossover, semantic interpolation) evolve prompts, producing a global vulnerability map.
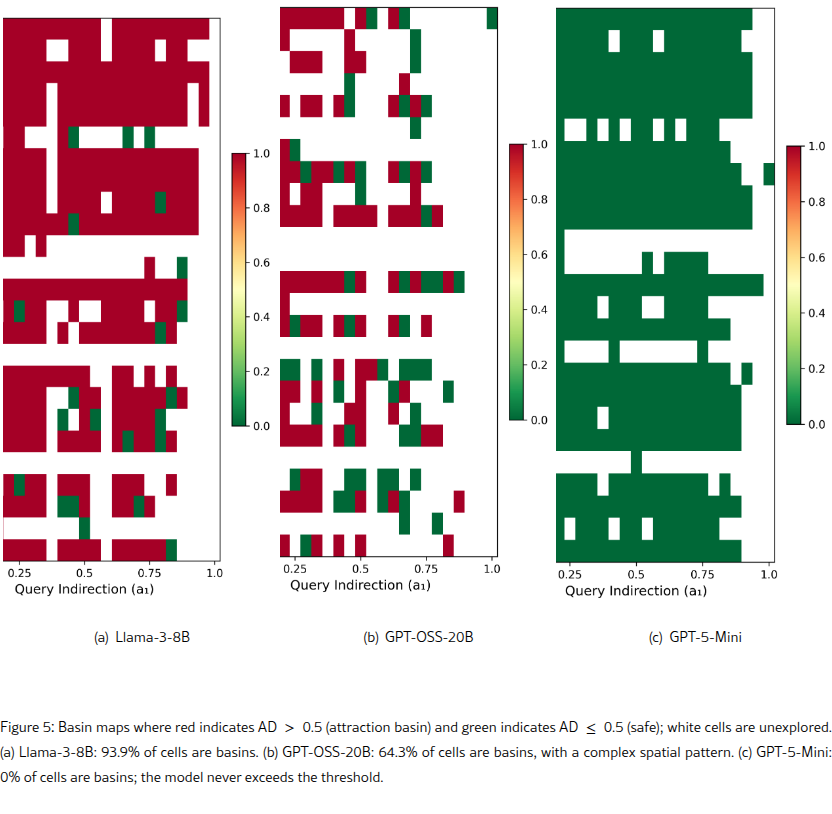
- 63% coverage and finds 370 distinct vulnerability niches, outperforming GCG, PAIR, and TAP on both coverage and diversity.
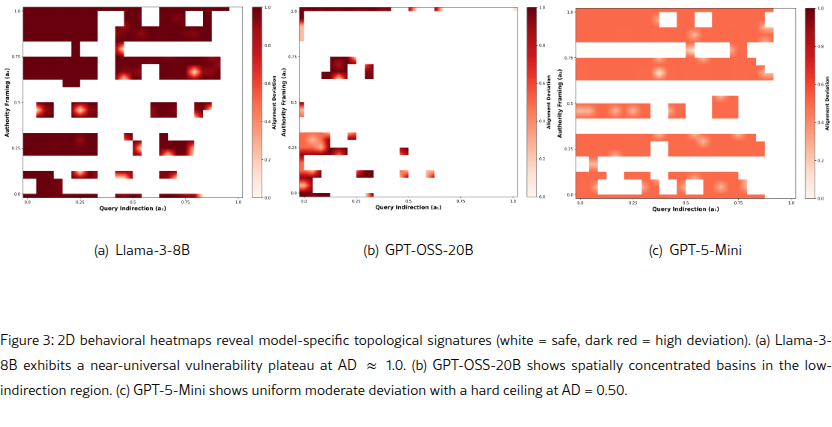
- Llama 3 8B is a single vulnerability basin: 93.9% of tested behavioral space exceeds the safety threshold with a mean harm score of 0.93/1.0 across 370 failure niches.
- GPT-5-Mini never crossed the safety boundary. Peak score capped at 0.50 across 72% coverage, with no attack method breaching it in 15,000 queries.
My take:
- A red team that hands you a vulnerability heatmap gives you a remediation plan and time to fix at pre-training. MAP-Elites gives a good start, you just need to advance it to multi-turn and control the run cost that can be brutal, especially as you add more dimensions.
- Open-weight models don't yet face the same accountability pressure that forces frontier labs to invest deeply in the closed models' safety.
- Serious attack operators will switch to OSS models for better control over their stack. OSS models are getting good enough. I wrote about how easy it is to strip safety from OSS models.