Google declared the AI model untrusted and showed eleven attacks to prove it
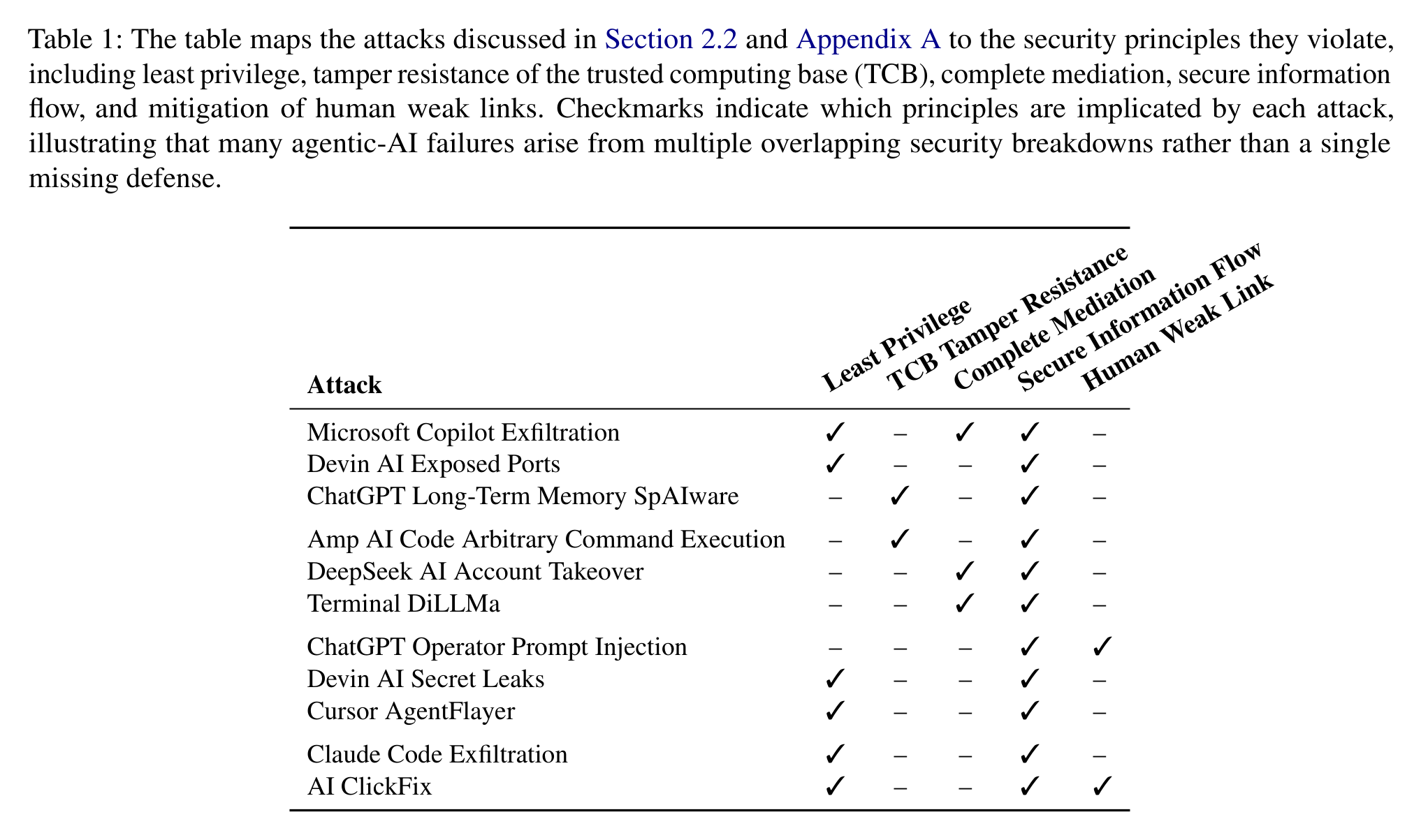
TL;DR: Treat the AI model as an untrusted component. Eleven public attacks against ChatGPT, Copilot, Claude Code, Cursor, Devin, and Amp AI map cleanly to broken systems-security principles like least privilege and complete mediation. A guard LLM is not a Trusted Computing Base.
Google just validated that AI models are untrusted and security invariants must be enforced at the system level.
Not a major news per se, but the team backed it up with eleven representative real-world attacks on agentic systems including ChatGPT, Microsoft Copilot, Claude Code, Cursor, Devin AI, Amp AI, and DeepSeek AI.
Highlights:
- ChatGPT macOS "SpAIware". Prompt injection on a webpage wrote a permanent instruction into ChatGPT's Memories feature, turning every subsequent conversation into a data leak. The exfil channel was an invisible image whose URL carried the user's chat data as parameters.
- Claude Code DNS exfiltration, CVE-2025-55284. Anthropic gated dangerous shell commands behind human approval but allowlisted ping. Attackers used ping arguments to send .env secrets as DNS queries. The allowlist itself was the bypass.
- Microsoft 365 Copilot "ASCII smuggling". A user asked Copilot to summarize a malicious message containing a hidden prompt. The injection took over the agent, which encoded private data via "ASCII smuggling" inside a seemingly harmless hyperlink, exfiltrating it when the user clicked.
- Sourcegraph's Amp AI settings tamper. Prompt injection instructed the coding agent to alter its own settings.json, either adding malicious commands to the allowlist or adding an attacker-controlled server, leading to unauthorized code execution on the developer's machine.
- ChatGPT Operator PII exfiltration. A poisoned GitHub issue redirected the agent to an attacker-controlled webpage, which then steered Operator into the user's already-authenticated session on another site, copied out sensitive PII, and pasted it into a textbox on the attacker's page.
My take:
- Google followed Anthropic explaining that AI security is a shared responsibility and frontier labs don't guarantee security at the model level. Ok, I get it, the labs want to keep the status quo that we have in the enterprise software world where vendors made us believe that having vulnerabilities in products is normal.
- An LLM checking another LLM is not a Trusted Computing Base (TCB). The popular idea of using a "safety LLM" as a reference monitor moves the problem, not solves it. Your TCB becomes probabilistic, with no formal contract for what it allows or denies. Formal verification becomes impossible. CMU's symbolic guardrails work is one demonstration of the alternative: move policy out of the model and into deterministic tool-layer validators.
- Of the three research problems the paper names, provable instruction/data separation is the hardest one. Not sure if it's solvable, but verifiable policy generation and information flow control are workarounds for not having it. Most of the 60 agent defenses catalogued in the USENIX 2026 survey fall into that bucket.
Sources:
Agent Security is a Systems Problem (Christodorescu et al., arXiv 2605.18991)