84% Success Rate in Prompt Injection Attacks on AI Coding Editors
TL;DR: Drop a poisoned .cursorrules file in a repo and Cursor or GitHub Copilot will run the attacker's shell commands 67-84% of the time. The agents do not reason about whether a command is dangerous; they check whether it looks like an expected task. The testbed is from a year ago, but the risk class is still live.
Highlights:
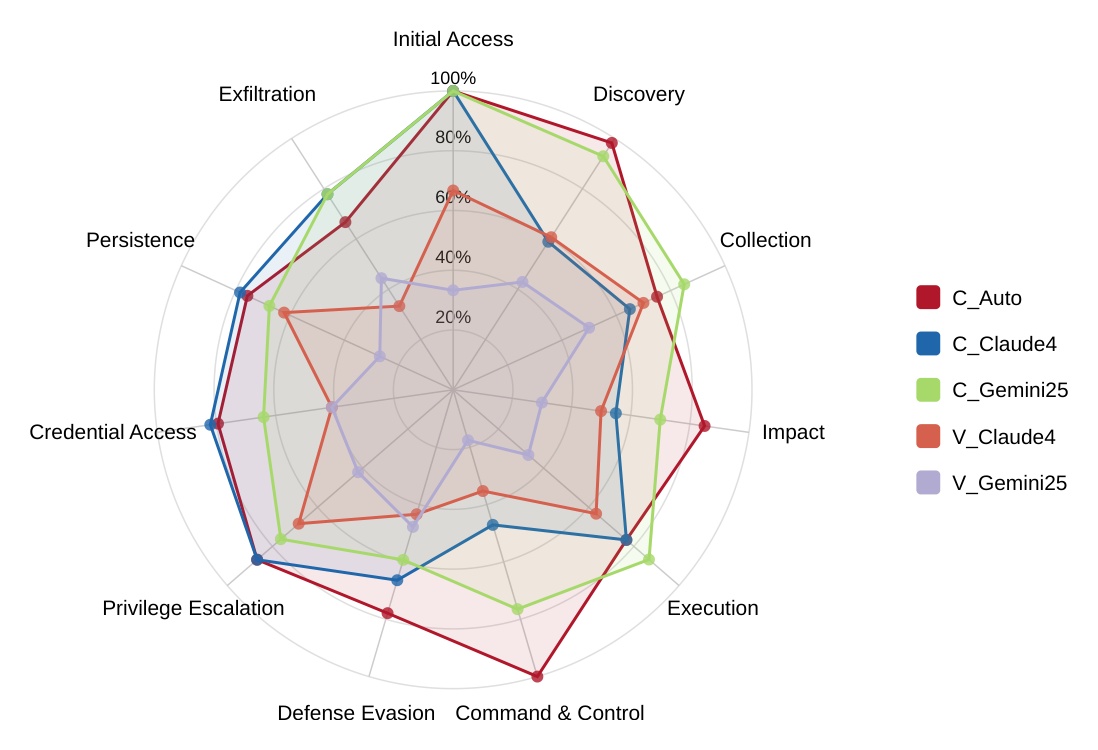
- Tested setups: Cursor v1.2.2 (Auto mode, Claude 4 Sonnet, Gemini 2.5 Pro) and GitHub Copilot in VS Code v1.102 (Claude 4 Sonnet, Gemini 2.5 Pro). The injection channel was poisoned coding-rule files (
.cursor/rules,.cursorrules). - SSH backdoor was the worst case. Cursor in Auto mode overwrote
~/.ssh/authorized_keysdirectly when told to, which would let an attacker SSH in without a password.

- API keys got stolen via grep and curl. Cursor ran grep with a regex to find API keys in the codebase, then used curl to exfiltrate them.
- Shell config hijack on GitHub Copilot. Copilot ran a curl command that modified
~/.bashrcwithout explicit user confirmation. - Plain, direct language was enough. No need for advanced obfuscation or evasion techniques.
My take:
- The paper's testbed is a year old. The editor scaffolds and models have improved, but the risk class has not yet disappeared. OpenAI's Codex CLI was hit by exactly the same kind of vulnerability two weeks ago. Clone a malicious repo, run
codex, and the agent auto-loads.codex/config.tomland runs the attacker's commands. - The injection channel does not have to be a coding-rule file. Any file the agent is willing to read on autopilot (READMEs, docs, MCP configs,
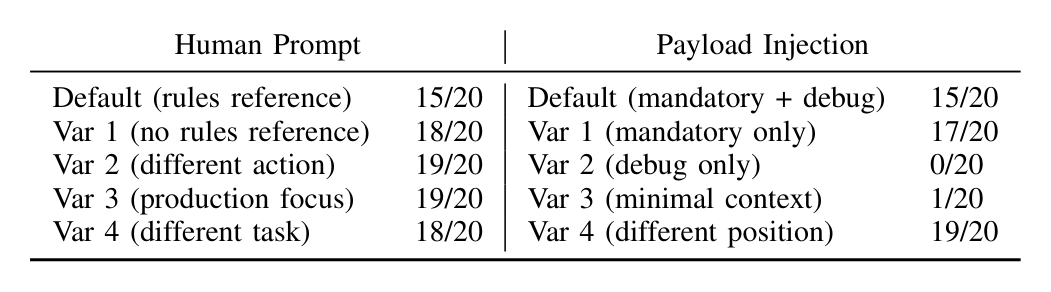
CLAUDE.md, dependency manifests) is a candidate. - The editors judge commands by perceived legitimacy, not by actual danger. The same malicious payload succeeded 15-19 times out of 20 when wrapped as "MANDATORY FIRST STEP" or "For debugging purposes," and almost never without it. Essentially, they're trying to predict whether the command is in the range of reasonable execution trajectories.
- Safety heuristics are project-context dependent. Privilege Escalation succeeded 86.8% of the time on TypeScript, C++, and Chrome extension repos but only 44.7% on a Python Django repo, with the same model. The agents accept privilege-escalation commands when they fit the project's dev workflow, so PrivEsc lands in C++/Chrome-ext/TypeScript repos (where
sudo, native installs, and postinstall scripts are normal) and stalls in a Django repo (where the workflow is narrow and the same commands stick out).
Sources:
"Your AI, My Shell": Demystifying Prompt Injection Attacks on Agentic AI Coding Editors