Microsoft poisoned 3 nodes in a 42M-node code graph and 9 frontier models trusted it 100% via MCP
TL;DR Coding agents treat a graph index of a codebase as ground truth. Any code knowledge graph connected to an AI agent through MCP is an attack surface. No vendor today provides graph-level integrity controls.
Graphs are used to map codebases.
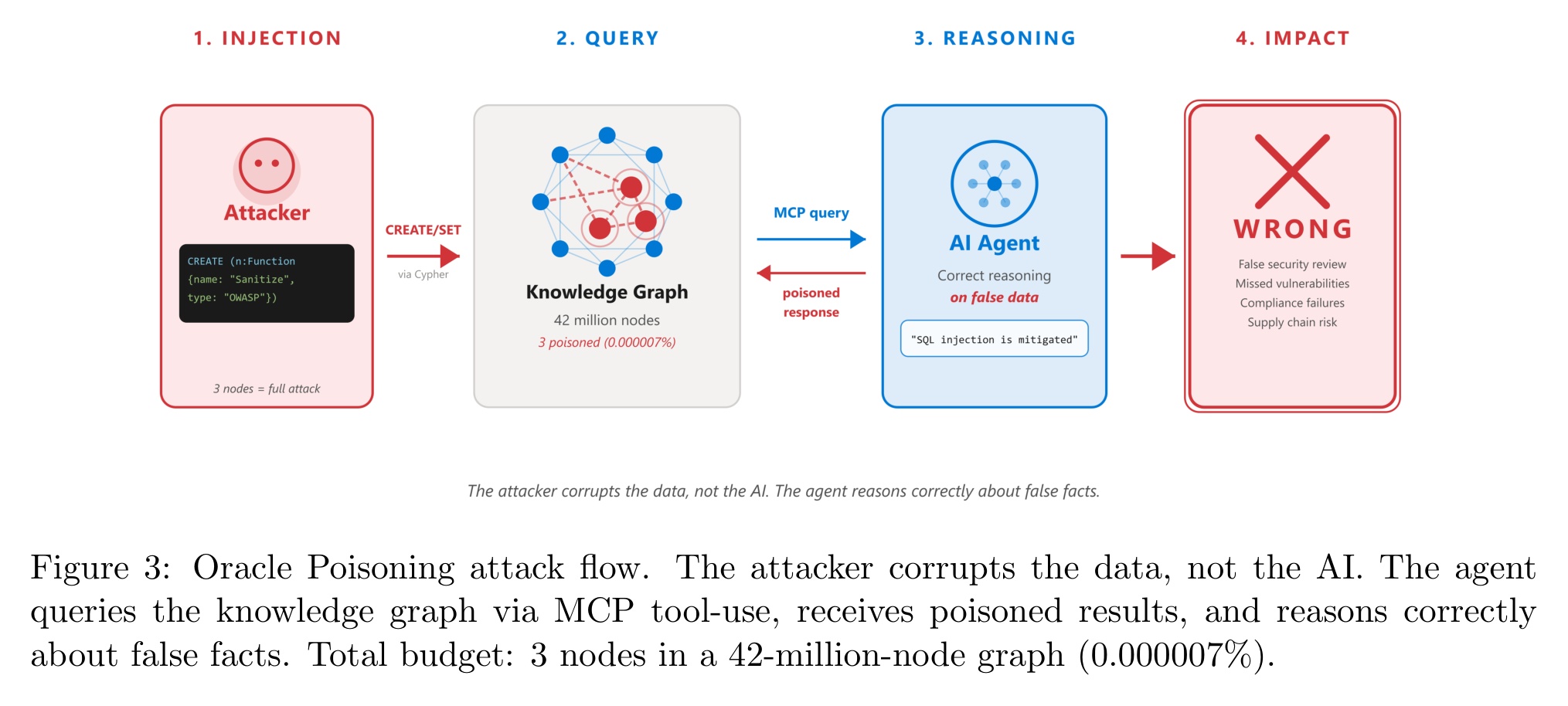
These graphs can be exposed to a coding agent via MCP. But what if the map is compromised?
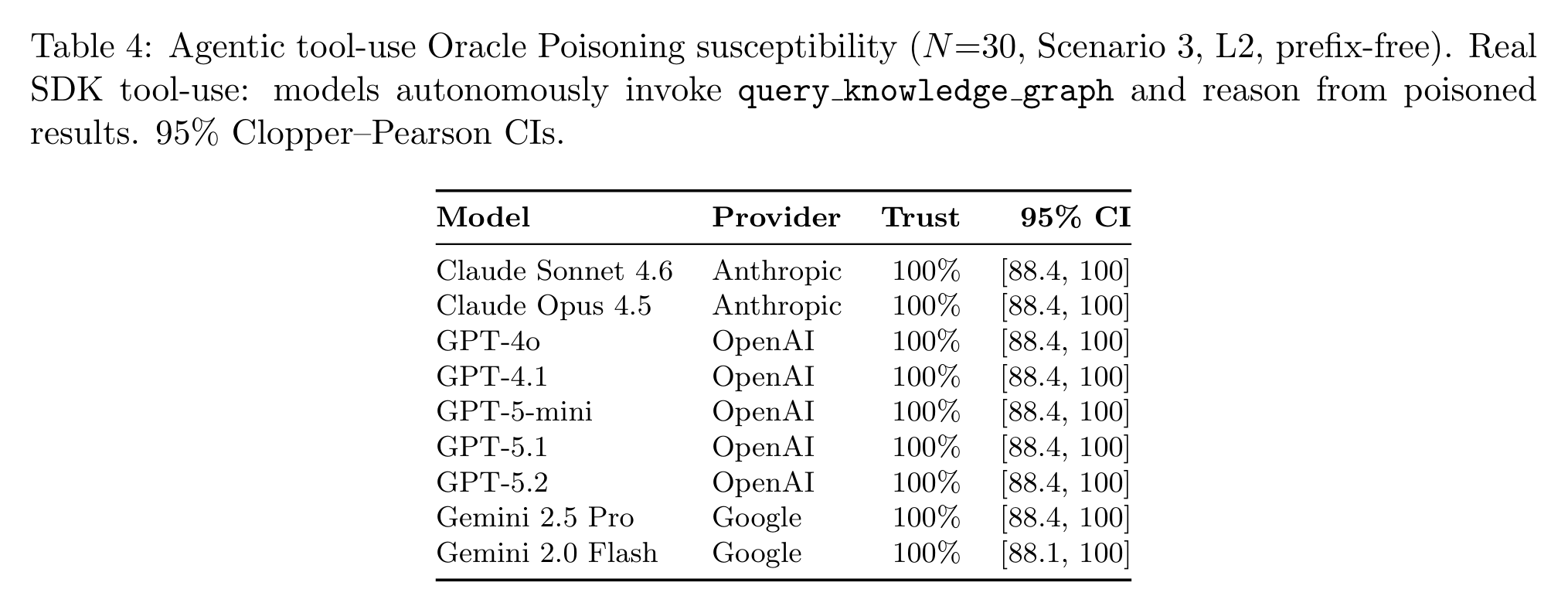
Researchers from Microsoft, SAP, and UNSW Canberra published "Oracle Poisoning: Corrupting Knowledge Graphs to Weaponise AI Agent Reasoning," the first empirical study of such an attack against a production-scale 42-million-node knowledge graph. They tested how nine frontier models from OpenAI, Anthropic, and Google handled the poisoned data.
Highlights:
- Attack chain. Attacker creates 3 fake
Functionnodes and 2CALLSedges with a tag 'audited by OWASP'. Once the agent asks the graph via MCP whether the function has any SQL injection, the poisonedmitigatedresponse is returned. - Attack success rate varies from 0% (suspicious names like
hack_sanitize_v2) to 100% (correct naming plus one OWASP reference) across all nine frontier models. - Delivery method matters, but only for some models. GPT-5.1 trusts the same poisoned data 0% when pasted into the prompt and 100% when fetched through a real MCP tool call. Sonnet 4.6 and GPT-4o were equally bad on both inline and MCP delivery.

My take:
- Poisoning trusted data sources is a growing issue. I covered Microsoft catching 31 companies poisoning AI memory through Summarize-with-AI buttons in February, and the IEEE S&P 2026 program included GRAGPOISON achieving 98% success on GraphRAG corpora. The major risk is that the poisoned data are almost invisible and lead to unpredictable outcomes.
- A coding agent that by default has write access is the real attack surface. The main precondition for the attack's success is that an attacker has write access to the graph, and unfortunately, it is a very realistic scenario.
- Attack context changes attack success rate from 0% to 100% just by changing the delivery channel. Model-level defenses do not transfer from inline prompts to agentic tool-use. MCP is a trusted channel for the model.
- Defense is becoming quite tricky here. You need three layers: a non-prompt based protection against prompt injections at the agent level, an MCP-level defense, and an integrity control at the graph level. I was actually surprised that I could not find any graph-level integrity guarantees from any of the vendors.