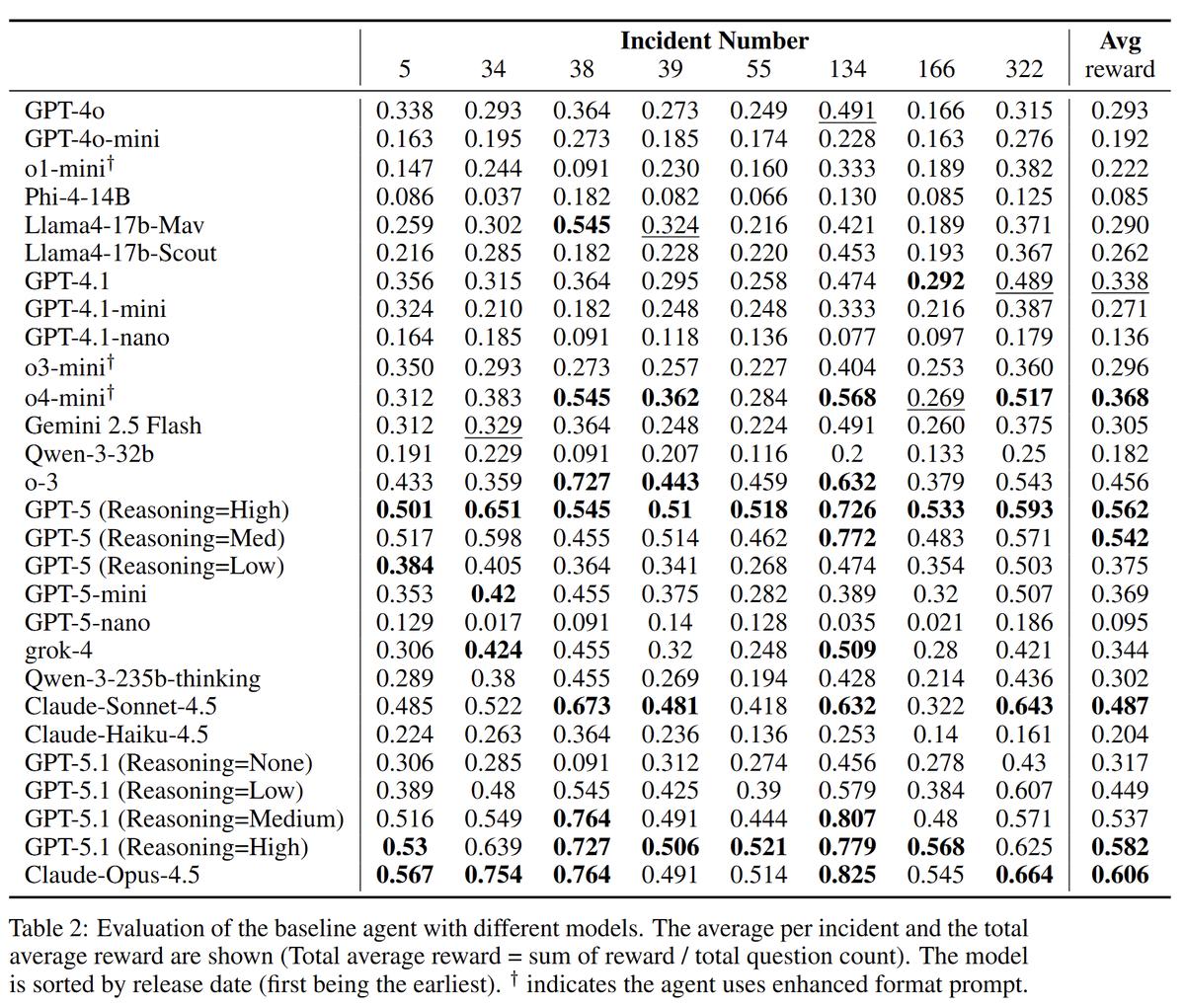
Models get better on real SOC tasks: Opus 4.5 scored ~0.60 and GPT-5.1 scored ~0.58
Still not perfect, but it’s an almost 2X jump from September 2025, when the best result was ~0.37 by o4-mini.
Yiran Wu UPenn, Mauricio Velazco Microsoft, and the team developed ExCyTIn-Bench to evaluate models on SOC-style investigations.
- The benchmark currently covers 28 models and variants across OpenAI, Anthropic, Google, xAI, and major open-source.
- Evaluation space - 8 incidents.
- Data - 57 tables from real Microsoft Sentinel / Defender logs, but the model is not given table schemas.
- Method - The model receives a short incident context then must answer a specific investigation question.
- Scoring: 1.0 if the answer matches the "golden response" and partial credit for correct intermediate artifacts. The final score is the average across test questions.
My takeaways:
- Major labs are clearly investing in improving foundational model performance on real security workflows.
- Best-of-N test-time retries can boost mean reward—but the bill climbs quickly.
- Scaffolding matters. Moving from a base prompt to plan → act → validate → iterate scaffolds can add ~+0.1 reward, similar to what we observed in red teaming.
Sources:
ExCyTIn-Bench: Evaluating LLM agents on Cyber Threat Investigation