Google's new audit shows 3 of 4 unlearning methods fail to forget
TL;DR: The only method that truly erases data keeps training on it under random labels. The clever alternatives leave fingerprints an output-only statistical test can detect. For frontier LLMs there is no affordable proof of forgetting yet: the audit itself requires a $100M+ retrain.
Google researchers asked a model to forget, but did it?
There are 4 main unlearning methods: fine-tuning, pruning, parameter dampening, and random-label. But there was no robust way to prove how well a model actually forgets.
So Mónica Ribero from Google Research built a framework to audit machine unlearning. It generalizes MMD, the field's default statistical test for comparing two sets of samples, co-invented by her co-author Arthur Gretton. The code is public.
Highlights:
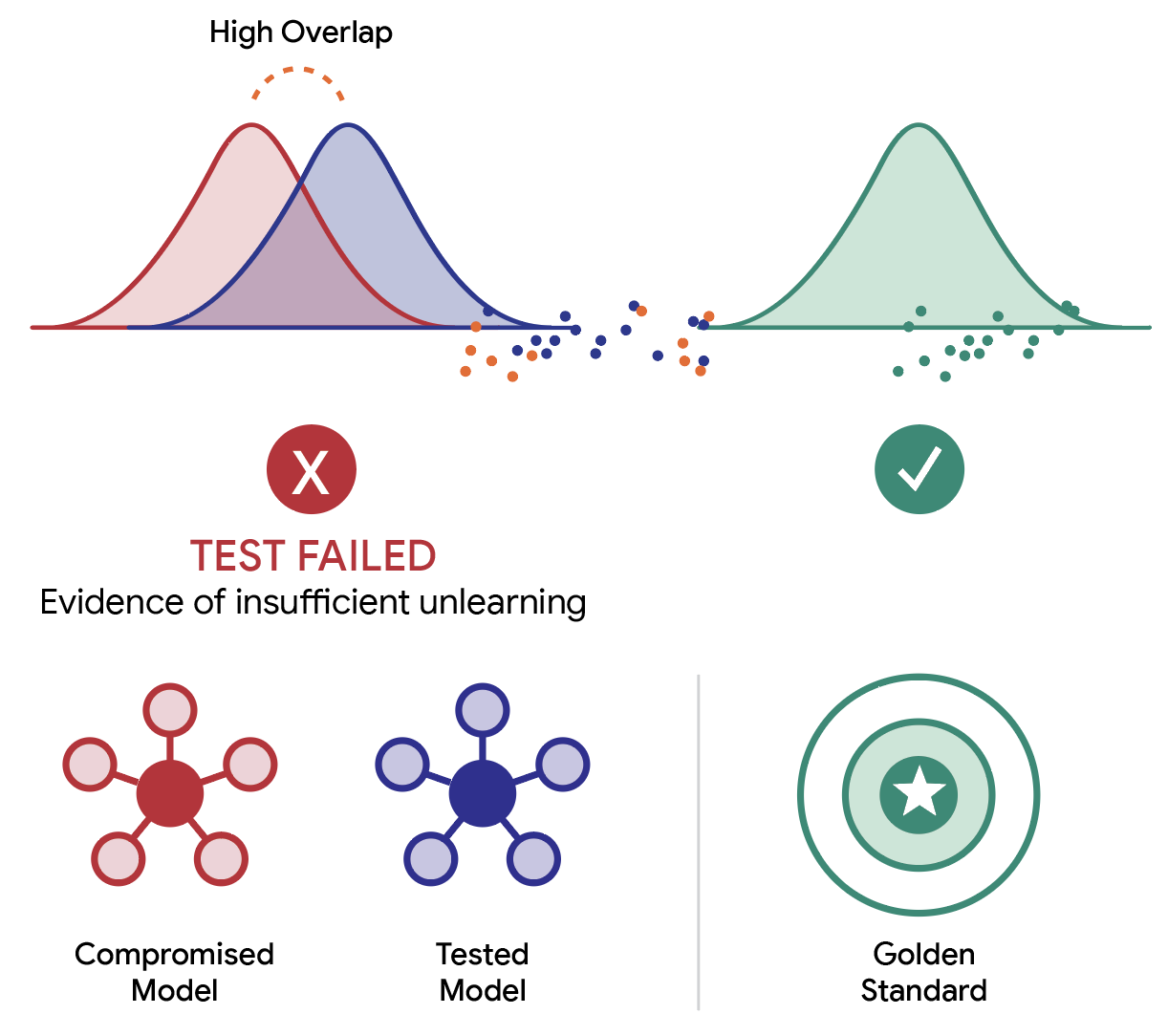
- The naive check: retrain the model from scratch without the forgotten data, then compare the two statistically. That method doesn't work, because training randomness simply makes two models look different.
- The fix is a three-way comparison. The audit measures the statistical difference between the tested model's outputs and two references: the retrained copy and the original that still contains the data. A smaller difference from the original means the data is still in there.
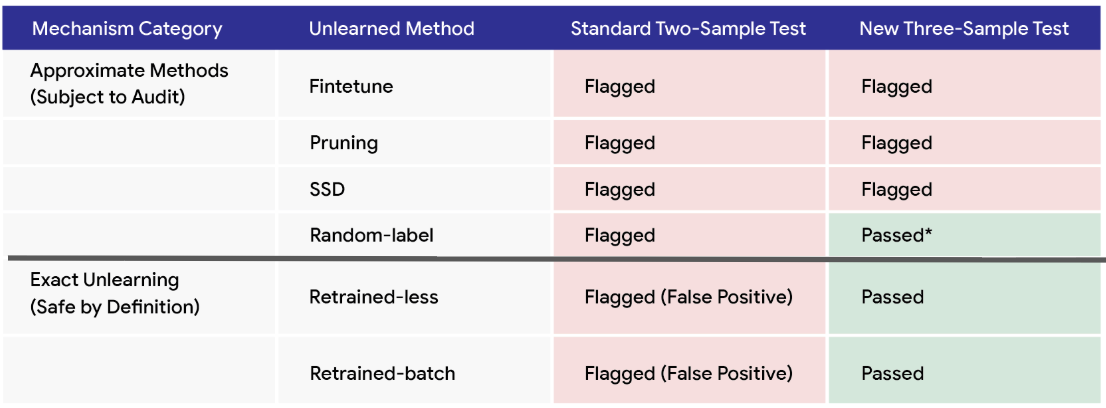
- The audit showed that on a small image classifier asked to forget 10 training images, fine-tuning, pruning, and parameter dampening failed. Only random-label unlearning worked, the method that keeps training on the forgotten images under random labels.
- The same audit catches broken differential privacy implementations with just 5,000 output samples vs the millions previous methods needed. Google's previous auditing library, DP-Auditorium, missed the flawed mechanism entirely. In the Cliopatra attack on Anthropic's Clio, differential privacy at epsilon 25 was the only defense that held, and a guarantee like that only protects if the implementation is correct.
My take:
- Model unlearning is a big deal, especially as part of compliance with privacy regulations. The burden of proof is on the model owner, and they need a mechanism to demonstrate that the data is really gone. A related need shows up after an attack: poisoned agent memories are hard to detect and weed out.
- The irony of random-label unlearning is that it makes the model forget the data by continuing to train on it.
- The catch-22: the audit needs outputs from a model retrained without the data, so proving you did not need to retrain requires doing the retraining anyway. That is fine for a small classifier and a fantasy for a frontier LLM, where a pretraining run costs $100M+.
Sources:
- Regularized f-Divergence Kernel Tests
- A new framework for auditing machine unlearning (Google Research blog)
- f_divergence_tests source code (google-research GitHub)
- DP-Auditorium: a Large Scale Library for Auditing Differential Privacy
- Researchers showed how to break Anthropic's Clio and extract 39% of medical diagnoses from its output (The Weather Report)