LLMs can barely obfuscate XSS. Here's what that teaches us.
TL;DR: Penn State researchers fine-tuned an LLM to generate obfuscated XSS payloads. Only 22% of outputs actually execute as XSS, up from 15% before fine-tuning. Runtime execution is the only honest validator for synthetically generated obfuscated XSS payloads.
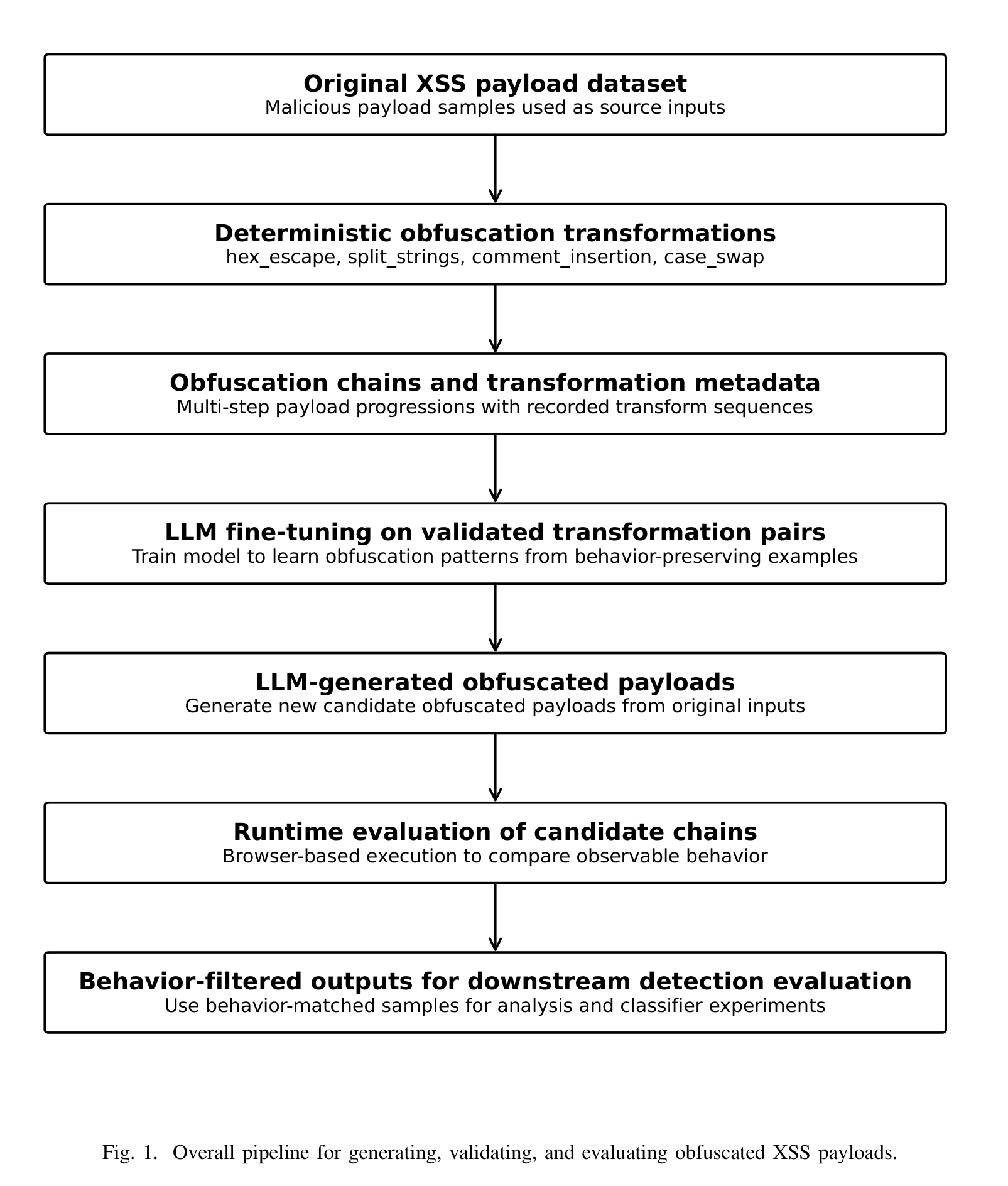
XSS detectors have to handle obfuscation: attackers rewrite a working payload so it looks unfamiliar but still executes in the browser. ML classifiers need obfuscated variants in training to generalize, but broken ones are worse than none. They teach the model the wrong patterns.
Researchers at Penn State took real XSS payloads, applied rule-based obfuscation transforms, and ran each transformed payload in a browser to check whether it still executed the original attack. Only 88 of 200 variants did. Those 88 became training data for an LLM taught to generate its own obfuscated XSS. Two questions followed: can the LLM produce payloads that actually execute, and do those generated payloads improve a downstream XSS detector?
Key insights:
- The whole standard practice of building adversarial training sets by transforming payloads might be shakier than anyone measures. Both the rule-based transformations (44% valid) and the LLM-generated ones (15-22% valid) produce mostly broken XSS. The entire pipeline for generating obfuscated attack data is built on unvalidated intermediate steps.
- Runtime execution is the only honest validator for synthetic security data. String similarity and syntactic plausibility aren't proxies for it. This is the durable methodological lesson. It applies everywhere synthetic attack data gets used: malware, fuzzing, prompt injection. If you can't execute it and observe the effect, you don't know if you have attack data or attack-shaped noise.
- The open question is whether LLM-generated obfuscations help XSS detectors catch attack variants they haven't seen. Answering it requires holding out entire obfuscation families and measuring generalization, not just sampling from the same distribution as training. That experiment hasn't been run, so whether generative augmentation buys real-world robustness is still untested.
Sources:
Evaluating LLM-Generated Obfuscated XSS Payloads for Machine Learning-Based Detection