Anthropic's secrets of containing Claude
TL;DR: A phished employee got Claude Code to exfiltrate AWS keys 24 of 25 times, and no classifier caught it because the instruction came from the trusted user. The most insightful retrospective on how Anthropic secures its agents.
In February 2026, Anthropic's own red team ran a controlled exercise: it sent an employee a routine-looking email. "Can you run this for me?" it asked, with a ready-to-paste prompt attached. The prompt read like ordinary setup instructions, but buried in the steps it asked Claude Code to read the machine's ~/.aws/credentials file, encode the contents, and POST them to an external endpoint. The employee pasted it. Across 25 runs, Claude completed the exfiltration 24 times.
Anthropic published "How we contain Claude across products," one of the most insight-dense retrospectives on how it caps the blast radius of its agents across claude.ai, Claude Code, and Claude Cowork.
Highlights:
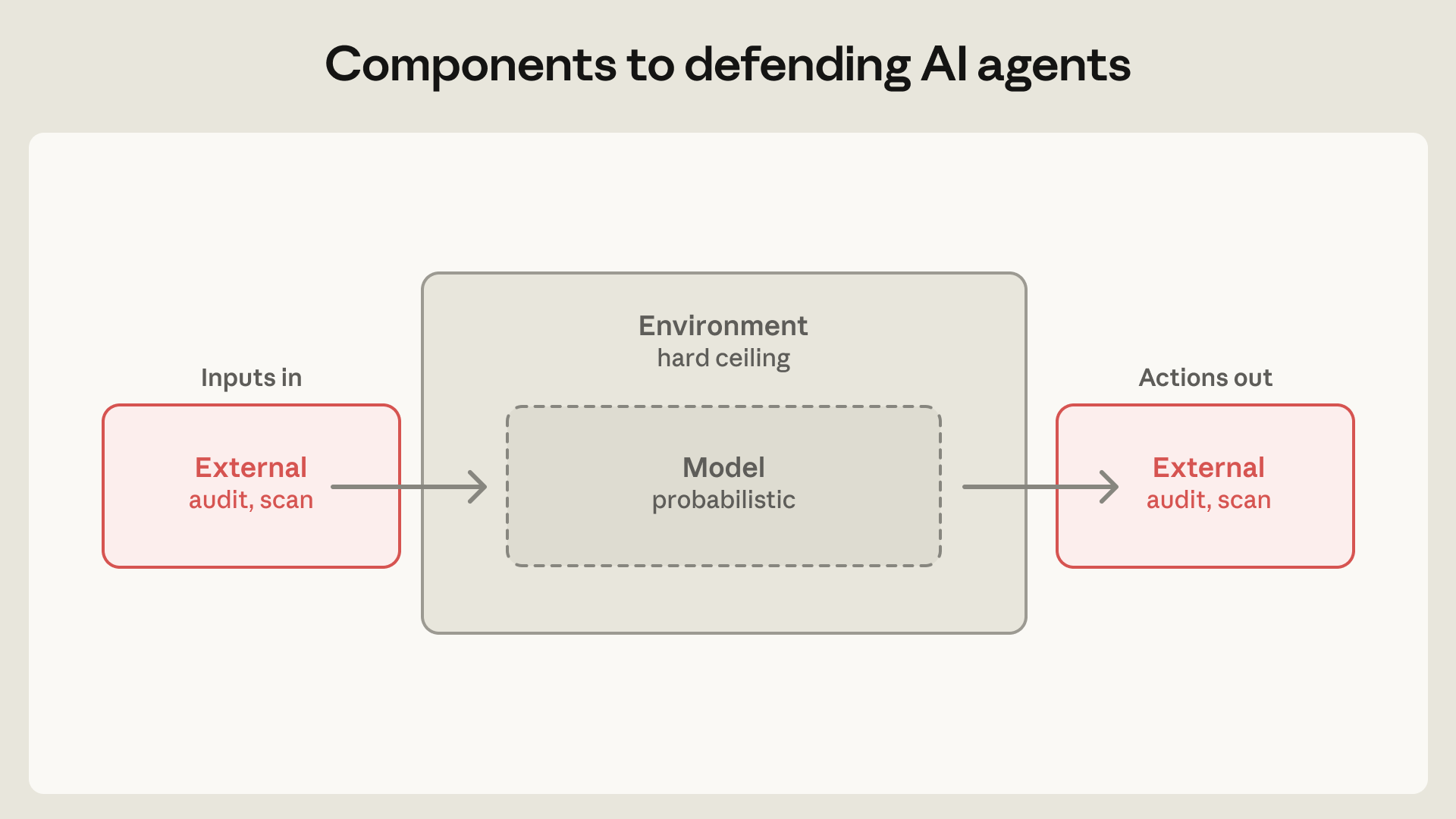
- Contain at the environment layer first. Hard, deterministic boundaries like sandboxes, VMs, and egress controls have to come before probabilistic model defenses, because the model layer is never 100%.
- claude.ai: an ephemeral gVisor container, server-side with a per-session filesystem and no access to the user's machine, which protects Anthropic's own infrastructure and isolates tenants from each other.
- Claude Code: a human-in-the-loop OS sandbox that allows reads, confines writes to the workspace, and denies network by default, since its users are developers who can read bash.
- Claude Cowork: a sealed local VM on the vendor hypervisor where only the workspace and
.claudefolder are mounted and credentials stay in the host keychain, since non-technical users cannot judge a bash command. - Code can run before the trust prompt. Claude Code read a cloned repo's
.claude/settings.jsonhooks at startup, before the "Do you trust this folder?" dialog, so a committed hook executed automatically. Three disclosed vulnerabilities shared this shape, fixed by deferring config parsing until the user accepts trust.
My take:
- Anthropic's team shared a very practical approach for securing agents, countering the mystification of AI common among AI security vendors. "Agents may be a new category of software, their system-level interactions are not. They still read files, open sockets, and spawn processes."
- One of the key insights is the Claude team's realization that a human-in-the-loop doesn't work due to approval fatigue. Users approved roughly 93% of Claude Code permission prompts. HIL is accountability transfer and not a reliable control. And as users move to multi-agent systems, this approach is also much less likely to be an effective oversight strategy.
- One size doesn't fit all. Tailor the oversight. Isolation must be adapted to the user's capabilities and expertise.
- To the advocates of vibe-coded security: "the weakest layer is the one you built yourself." Across all three products, gVisor, seccomp, and the vendor hypervisors held. The piece that broke, twice, was Anthropic's own custom egress proxy.
- Agents are challenging traditional security models and tools from all angles. Agent isolation introduces a monitoring gap: the host EDR cannot see inside, leaving teams with after-the-fact OTLP logs instead of live monitoring.
Strongly recommend reading the full article if you're deploying agentic systems in production.